스파르타 캠프 1주차를 마치며
KPT 회고
: Keep Problem Try의 약자로 회고 내용을 세 가지 관점으로 분류하여 회고를 진행한다는 것
Keep :
현재 만족하고 있는 부분
계속 이어갔으면 하는 부분
Problem :
불편하게 느끼는 부분
개선이 필요하다고 생각되는 부분
Try :
Problem에 대한 해결책
다음 회고 때 판별 가능한 것
당장 실행가능한것
Keep :
1. 팀원과의 소통을 통해 협업 스킬을 늘릴 수 있어 좋음
2. 팀이라는 구심점이 있다보니 서로 뭉치고 의기투합하게 되어 좋음
3. 팀원과의 과제는 꾸준히 있었으면 좋겠음
4. 개인별 장점을 서로 공유할 수 있어 육각형 인재가 될 좋은 기회같음
5. 궁금한 것이 생기면 언제든 질문이 가능하다는 장점
6.개선중인 나의 단점의 한계를 깨달을 수 있어서 좋았다
Problem :
1. 개인별 팀 프로젝트에 관한 중요성 정도의 차이가 발생함 그로 인해 쓸데없는 비교를 하게 되어 팀원간의 화합을 해침
2. 궁금한 것이 생기면 언제든 질문이 가능하다는 장점이 있으나 그로인해 담당 튜터님이 다른 업무 중이시면 계속 기다려야 한다는 단점이 있음
3. 상대적으로 사양이 낮은 컴퓨터를 사용하는 학생의 경우 렉, 튕김 등 의 현상이 일어나 팀간 의사소통하는데 에로사항이 생김
4. 배운 내용의 경우 어느정도 이해가 되고 자료 정리도 가능한데 배운 내용이 아니면 바로 붕 뜨게됨 집중이 부족함
Try :
problem 1.
-> 해당 프로젝트의 중요성 상기 및 이를 통해 프로젝트를 완수하기만 해도 혹은 모범적으로 완수 시 어느 정도의 가능성을 열게 되는건지 부수적인 설명 필요
problem 2.
->오히려 담당 튜터님이 자리에 계실땐 질문 가능한 시간을 기재해두어(ex)입구 앞 게시판) 질문자/튜터님 둘 다에게 효율적인 시간 사용
problem 3.
->
1) zep 의 간소화하여 프로그램을 좀 더 가볍게 제작
2) 강의 시작 전 개인별 필요 기본 사양(컴퓨터,노트북 등)을 기재하여 본인이 기본 사양에 미치지 못할 시 자발적으로 대여 서비스를 이용하도록 공지
problem 4.
->
알람을 설치하고 적은 시간부터 설정해 집중하는 시간을 늘려보자
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
데이터 분석 5주차 7 & 숙제
8-1) 데이터 시각화
8-1-1) 피벗 테이블 만들기
- 피벗 테이블 : 데이터 통계를 보다 쉽게 파악 할수 있도록 만든 테이블
- 기존의 데이터를 바탕으로 필드를 재구성해, 데이터 통계를 보다 쉽게 파악 할수 있도록 만든 테이블

사용 데이터 cohort_data
사용 코드 pivot
코드
#행,열,값 지정
cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_counts
8-1-2) 좀 더 가시화 시키기 ( 데이터 %화->리텐션 테이블 만들기)
- 리텐션 : 고객이 우리 제품이나 서비스를 지속적으로 소비하는 것
8-1-2-1) 리텐션 테이블 생성 및 각 데이터에 나눠줄 수강 첫 주 총인원 구하기
사용 데이터 cohort_counts
사용 코드 iloc
코드
# 앞서 만든 피벗 테이블을 retention 변수에 저장하기
retention = cohort_counts
#각 주(week) 별 최초 수강생 수만 가져오기 (나눠줄때, 분모가 되는 부분!)
# : 는 모든 행을 뜻함, 0은 첫번째 열을 뜻함
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
결과

8-1-2-2) 각 데이터에 수강 시작 주의 총 인원 나눠주기
필요 데이터 cohort_counts
필요 코드 divide
코드
# 표의 단일 데이터에 최초 수강생의 수를 나누어, 각 주당 수강생 수강율 나타내기!
#cohort_counts를 cohort_sizes에서 axis=0 첫번째 열로 나눈다
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention.head()
결과

8-1-2-3) 코호트 분석 히트맵으로 시각화 하기
* 히트맵을 사용하려면, 우선 seaborn 라이브러리를 불러 오는 것이 필요
필요 데이터 retention
필요 코드 heatmap / figure / x,ylabel / x,yticks / show
코드
plt.figure(figsize=(10,8))
sns.heatmap(data=retention,
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
plt.yticks(rotation=360)
plt.show()
(참고)
sns.heatmap(data="필요한 데이터 입력하기",
annot=True, #각 cell의 데이터 표기 유무를 나타냅니다!
fmt='.0%', #values(데이터의 값) 값의 소수점 표기
vmin=0,#최소값 설정
vmax=1,#최댓값 설정
cmap="BuGn" #히트맵의 색을 설정합니다 )
결과

8-1) 최종 코드
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
sparta_data = pd.read_table('파일경로',sep=',')
sparta_data.tail()
format='%Y-%m-%d %H:%M:%S.%f'
sparta_data['start_time'] = pd.to_datetime(sparta_data['created_at'],infer_datetime_format=True)
sparta_data.tail()
sparta_data['start_week']= sparta_data['start_time'].dt.isocalendar().week
sparta_data.tail()
category_range = set(sparta_data['start_week'])
category_range
progress_rate = list(sparta_data['progress_rate'])
progress_rate
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
labes=[0,1,2,3,4,5]
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labes)
cuts
cuts = pd.DataFrame(cuts)
cuts.tail()
sparta_data = pd.concat([sparta_data,cuts],axis=1, join='inner')
sparta_data.head()
sparta_data.columns=['created_at','user_id','name','progress_rate','start_time','start_week',"week"]
sparta_data.head()
grouping = sparta_data.groupby(['start_week','week'])
grouping.head()
cohort_data = grouping['user_id'].apply(pd.Series.nunique)
cohort_data = pd.DataFrame(cohort_data)
cohort_data.head(10)
k=31
for i in range(6):
for j in range(5, 0, -1):
cohort_data.at[(k,j-1), 'user_id'] = int(cohort_data.at[(k,j),'user_id']) + int(cohort_data.at[(k,j-1),'user_id'])
k=k+1
cohort_data = cohort_data.reset_index()
cohort_data.head()
cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_counts
retention = cohort_counts
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention
retention.round(3)*100
plt.figure(figsize=(10,8))
sns.heatmap(data="필요한 데이터 입력하기",
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
plt.yticks(rotation=360)
plt.show()
--------------------------------------------------> 5주차 끝 숙제 시작
숙제 :
방금 만든 코호트 차트는 처음 인원별로 나눈 그래프(분모 처음 인원)이다
하지만 직전 주차간의 변화량은 알아보기 어려워 이번엔 직전 주차별로 나눈 그래프를 만들어보자(분모 직전 주차인원)
힌트!

수정 전 코드(틀림)
k=31
for i in range(6): for j in range(5, 0, -1): cohort_data.at[(k,j-1), 'user_id'] = int(cohort_data.at[(k,j),'user_id']) + int(cohort_data.at[(k,j-1),'user_id']) k=k+1
수정 후 코드
k=31for i in range(6):for j in range(5, 1, -1): retention.at[(k,j)] = retention.at[(k,j)]/retention.at[(k,j-1)] k=k+1
완성 코드
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
sparta_data = pd.read_table('파일경로',sep=',')
sparta_data.tail()
format='%Y-%m-%d %H:%M:%S.%f'
sparta_data['start_time'] = pd.to_datetime(sparta_data['created_at'],infer_datetime_format=True)
sparta_data.tail()
sparta_data['start_week']= sparta_data['start_time'].dt.isocalendar().week
sparta_data.tail()
category_range = set(sparta_data['start_week'])
category_range
progress_rate = list(sparta_data['progress_rate'])
progress_rate
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
labes=[0,1,2,3,4,5]
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labes)
cuts
cuts = pd.DataFrame(cuts)
cuts.tail()
sparta_data = pd.concat([sparta_data,cuts],axis=1, join='inner')
sparta_data.head()
sparta_data.columns=['created_at','user_id','name','progress_rate','start_time','start_week',"week"]
sparta_data.head()
grouping = sparta_data.groupby(['start_week','week'])
grouping.head()
cohort_data = grouping['user_id'].apply(pd.Series.nunique)
cohort_data = pd.DataFrame(cohort_data)
cohort_data.head(10)
k=31
for i in range(6):
for j in range(5, 0, -1):
cohort_data.at[(k,j-1), 'user_id'] = int(cohort_data.at[(k,j),'user_id']) + int(cohort_data.at[(k,j-1),'user_id'])
k=k+1
cohort_data = cohort_data.reset_index()
cohort_data.head()
cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_counts
retention = cohort_counts
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention
retention.round(3)*100
#주차별 수강 전환율 구하기
w=31
for i in range(6):
for j in range(5, 1, -1):
retention.at[(w,j)] = retention.at[(w,j)]/retention.at[(w,j-1)]
w=w+1
retention
plt.figure(figsize=(10,8))
sns.heatmap(data=retention,
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.title('개강일별 주차 간 전환율', fontsize=20)
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
plt.yticks(rotation=360)
plt.show()
5주차 복습을 마치며 느낀점
처음,두번째 강의 땐 무슨 말인지 이해가 안됐는데 세번째 강의를 들으니 이해가 간다
공부 방법을 이것저것 섞어봤는데 (처음, 두번째 강의 위주/세번째 강의 자료 위주)
목적을 이뤄 기분이 좋음
더 효율적인 방법은 없었을까 하는 고민도 드는데 현재 나에겐 이게 베스트다
더 수업에 효율적인 방법을 고민해봐야겠다 + 뿌듯!!
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
커리어 스터디 발표
발표자는 사다리 타기로 다른 팀원이 걸렸는데
해당 팀원이 발표 전날부터 발표 준비를 해 당일 리허설 매우 훌륭훌륭
과제 준비하는 과정에서 마찰도 있었지만 막상 끝내놓고 보니 아주 뿌듯함
막간의 발표 수정 자료
- Data 활용 직무 세 가지의 공통점과 차이점
공통점
- 의사소통 능력 필수
- : 다른 직군의 작업자들 또는 고객사와의 협업이 기본
- 수학적 / 통계학적 지식 필요
- : 문서를 통한 정보 습득 및 작성을 하므로 필요함
- 세가지 직업군 모두 데이터를 활용하여 문제를 해결
차이점
- 연봉
데이터 분석가 - 경영 / 비즈니스 직군 (출처: 원티드.2021)
- 초봉 3357만
- 5년 차 5051만
- 10년 차 7231만
품질관리 - 생산 (출처: 사람인.2024)
- 초봉 3309만
- 5년 차 3802만
- 10년 차 4147만
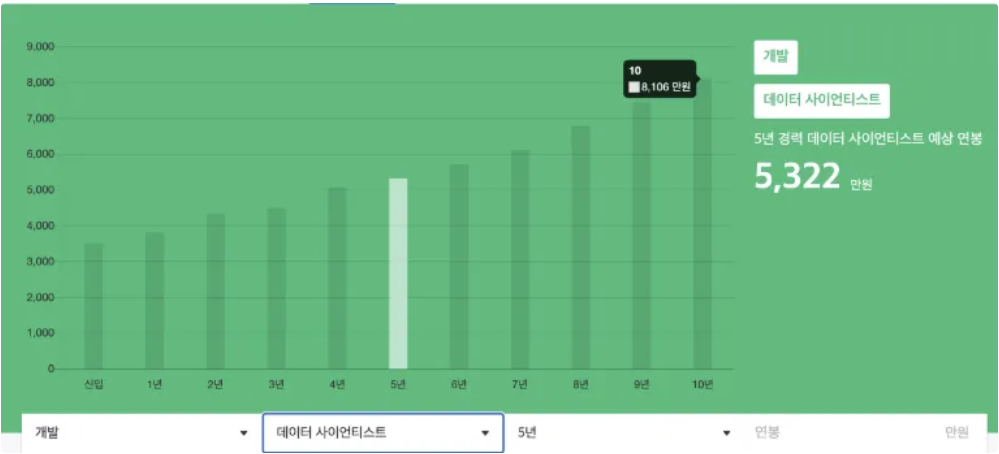
데이터 사이언티스트 - 개발직군 (출처: 원티드.2021)
- 초봉 3509만
- 5년 차 5322만
- 10년 차 8106만

2. 데이터 분석의 관점
데이터 분석가 : ‘과거’의 데이터를 분석하여 기획 및 시각화
품질관리 : ‘현재’ 생산하는 제품이 비즈니스 요구 사항과 내부 규정을 충족하는지 등의 운영 기능 평가
데이터 사이언티스트 : 비즈니스 질문에 머신러닝 모델을 통한 ‘미래’ 예측을 제공
3. 결과물의 차이
데이터 분석가
데이터를 분석하고 시각화하여 비즈니스 인사이트를 제공
품질관리
제조 공정 데이터를 활용하여 품질 기준 매뉴얼, 불량률 감소 계획, 공정 최적화 보고서와 같은 결과물을 작성, 이를 통한 공정 개선
데이터 사이언티스트
복잡한 문제를 해결하기 위해 머신러닝 및 딥러닝 모델을 개발
예측 및 최적화 솔루션을 제시하는 결과를 도출
- 비즈니스 인사이트(Business Insight): 비즈니스 환경과 시장 동향에 대한 깊은 이해와 분석
도메인별 공정 데이터를 활용하는 방법의 공통점과 차이점
공통점
- 공정 최적화를 위해 작업자 행동 데이터 수집 및 분석
- 양질의 품질과 합리적인 원자재 공급을 위한 관련 데이터 분석을 통해 최적의 납품처 선택
- 환경 및 보건 관리를 위한 공정에서 발생한 오염물질, 불순물 데이터 모니터링
차이점
- 각 도메인별 데이터 분석 요인이 다름
2차 전지

배터리 충전 및 방전 속도(C-rate)에 따라 충/방전을 여러 번 진행하였을 때, 배터리 용량의 유지 정도를 나타낸 그래프
철강 산업

열처리 온도가 상승함에 따라 후처리 강도가 낮아짐을 나타낸 그래프
반도체 산업
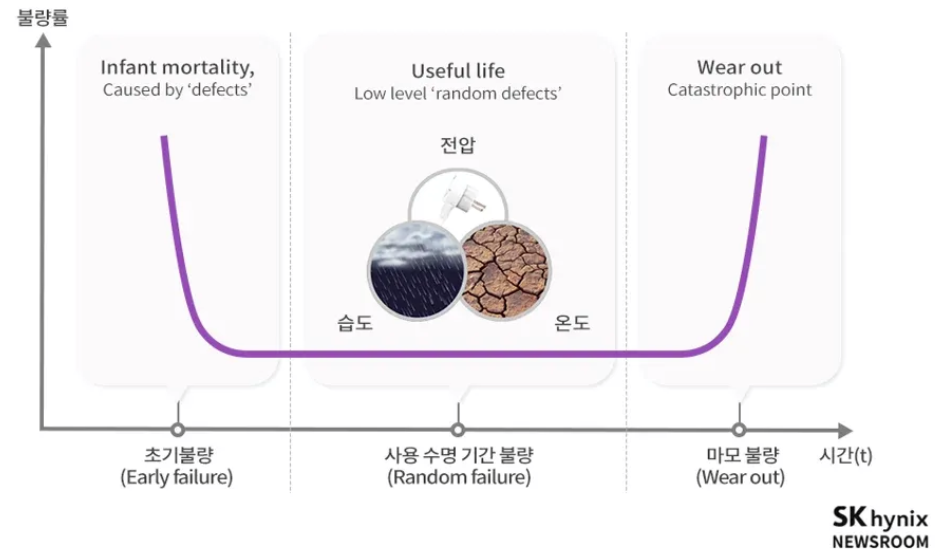
제품 수명 동안의 불량률을 시간 함수로 표현한 욕조그래프
수명 초기에는 제품 제조상 불량 때문에 생기는 초기불량이 많고, 제조 상에서 생기는 불량이 사라지면 제품을 사용하는 동안 불량률이 낮아짐. 제품의 수명이 다하면 다시 불량률이 높아지는 것을 확인할 수 있음 이러한 Burn-in을 통해 제품이 가지고 있는 잠재적인 불량을 유도하여 초기 불량을 미리 선별 가능
의약품 산업
<혈중 약물농도-시간 곡선하의 면적>

시간에 따른 약물 농도를 표현한 AUC(Area Under the ROC Curve) 그래프
- AUC=곡선 아래 면적=약물의 생체 흡수율과 전신순환에 도달한 활성약물의 총량
발표 느낀점 & 배운점
11조
느낀점 & 피드백
팀원별 관심 직무 및 도메인을 엑셀 도표를 활용해 기재함 (이게 인사말 여기부터 꺾임)
: 이런 방법이 있었지!
글자 크기 폰트 수정해둠 (노션에서 못 찾았는데 있는 기능이였나봄)
데이터 관련 검색량이 어마어마함
PT에서 강점이 있으셨는지 정말 괜찮은 자료였다
발표자 비유가 너무 알잘딱
1조
느낀점 & 피드백
PPT를 사용하여 편하게 진행
2차 전지 치우쳐져 발표가 이뤄짐
현업에서도 QAQC는 외부적인 감사기준인데, FDA는 기본, 머신러닝, 박스플락, 시각화해서 많이 쳐내는 식으로 진행, 각 도메인마다 그렇게 ... 잘들었다
자료 잘 만들어줘서 좋았음. 차이점을 비교하는 전표에서 도메인별로 화면에 보이게 정리한게 좋았음
발표할때 차분하고 좋은 발표였다 끝
12조
느낀점 & 피드백
PPT사용 전문적이라기보단 단순한 느낌
자료 조사도 비슷비슷? 한데
이쯤되니까 느껴지는건 자료 조사 주제를 너무 매니저님이 정한 주제에 국한됐단 생각이 듦
그치만 중요하다 생각해서 넣기보단 내용을 채우기 위한 자료란 생각이 들어 아쉬움
자료가 너무 많음 질림..
공정 별 차이점 에 1. 데이터 유형 생각했었는데 2. 주요 목적 3. 규제 및 관리 기준은 생각 못해봄
아쉬운점 .
1. 공정 플로우 그림은 좋았으나 설명이 아쉬웠음 하지만 뒷부분에서 데이터 설명이 또 있었어서
차라리 합치지 왜 안합쳤냐
2. ISO국제표준 잘 짚어서 잘 넣음 / 식품 쪽은 최근 이슈 같은 예시를 넣었으면 좋았겠다
10조
PPT씀
데이터 사이언스에 대한 설명이 있는데 아주 좋음
데이터 사이언스: 인공지능의 하위 개념 ~~
차이점 데이터 활용 목적 / 데이터 유형 / 데이터 분석 방식 / 등
마지막 느낀점을 따로 기재해서 잘배웠단 내용을 넣어줌
자료조사 좋고 조사에서 끝난게 아니라 분석을 엄청 잘하심 목소리 톤도 차분하고 좋았다
데이터에 직중에서 잘 설명한 부분 QC부분과 DS 부분 나눠서 설명한게 인상적 / 데이터에 대한 이해가 많이 필요하다
데이터가 없는 상황에서도 자꾸 ~~ 타겟값을 맞추기 위한게 DS분야인데 얼마나 영향을 미치는지 확인한다
QC 에도 에너지가 쏠리고 있다 ㅇ/// 데이터 부분에 집중해 발표한 것이 인상깊었다
6조
PPT 사용
데이터 관리 품질관리자 위주로 찾아봄
서사가 깔끔함
공정에 관한 설명이 많음 이해가 됨 설명에 국한된게 아니라 이를 통해 얻을 수 있는 데이터 그리고 활용 가능성 등을 기술함 / QnA를 따로 두어서 물어볼 시간을 가짐 -> 발표 자료에 대한 자신감
피드백
QC관련 일이 업데이트가 됐음 관심 가져봤음 좋겠음
전반적인 제조업에서는 매출이 중요 전기차/자동차 배터리 실린더리 같은걸 가지고 전반적으로 이런게 다르다 라고 예시 들기 / 같으 ㄴ업계로 보면 설명이 될것같고 / 도메인은 다 달라질 수 있는데 결국 상식이 없으면 인사이트 도출하기가 힘듦 그래서 관심도와 이해도가 높아보여 보기 좋았다 /
LG Display를 포함한 전 계열사에 2022년부터 확대전개된 LG만의 빅데이터 기반 6시그마 DX SS(Digital Transformation Six Sigma) 방법론 입니다. 다른분들도 조사해보시면 좋을거같습니다.(데이터분석가랑 다른게없어보이는...느낌입니다) ★ ★ ★ ★ ★알아보자 ★ ★ ★ ★ ★ ★ ★ ★
2조
PPT
바이오 의약품에 대한 설명으로 시작
바이오 의약품 종류 등 기재 / 자료 준비가 잘됐음
발표도 깔끔하고 눈으로 보기도 편함 / 자료 준비도 알잘딱하게 잘 준비함
각 공정별 직종별 데이터 분석법과 최종 결론을 어떤 식으로 이뤄지는지 정리한 내용이 너무 이해 잘되고 보기 좋음
전체적으로 7주(우리조) 발전 버전이란 느낌이 듦
DA DS QC가 비슷한데 도매인 별로 좀 다를 수 있음 여러 사례를 분석적으로 나타낸게 보기 좋았음
바이오 도메인 집중 타겟으로 잡음 그래서 각 포지션 별로 잘 알아볼 수 있는 좋은 자료였음
똑같은 기술을 배우는 사람들이지만 결국 하는 일이 좀 다른거 뿐이라 툴 습득을 통해 내가 어떻게 적성이 각각의 페이지와 맞는지 확인할 필요는 있음
지금까지 조사한 도메인이 전문적인 영역이라 자기 전문으로 커리어를 구상하면 좋을지 생각해보자
3조
PPT 사용
우리랑 비슷 단, 사진 자료가 같이 올라감
데이터 적으로 전문적으로 찾아본것이 없어 아쉬웠다
예시를 찾아보면 좋았겠다 아쉽다
9조
팀명이 너무 귀여움
데이터를 조금 더 집중적으로 알아봤으면 하는 아쉬움이 있었음
이번 과정에서 배울 수 있는 기술은 그저 수단일뿐 스스로 도메인 찾아서 내가 자신을 살 찌워라
머신러닝, 딥러닝, 삼전에서 전사원 DX를 하고 있음 데이터로서 대화할 때도 시각화를 첨부하게 되어있음
데이터를 이해하거나 해석능력이 떨어지면 떨어지게 되있음 -> 왜 반도체에는 도입이 늦었을까??
반도체 데이터가 웨이퍼에 디텍트 검사를 ~ 반도체 불량률이 높음 불량 낮추는(수율 높이는)결정적인 요인
5조
PPT씀
폰트 설정이 없음
준비 가볍게 이룸
의료기기라는 신박한 도메인을 가져옴
대본은 긴데 PPT자료는 너무 짧아서 아쉬움
핵심적인 내용은 잘 포함함 / 시간을 많이 안들이면서도 플레이어 구체적인 회사를 찾아서 자료를 찾아보는것이 좋다 / 어떤 직무가 됐든 최종 결과물로 소통하게 되는데 대쉬보드에 어떤 것을 넣을지 어떤 식이 효율적인지 곰니한 부분이 맘에 들었음
삼전 외 다른 대기업 모두 데이터 관련 내용을 교육하고 있음 나중에 딥하게 키워서 인사이트를 키워라
8조
제약 의료기기 제약 업무 관련 자료 데이터를 다양하게 준비함
별개의 피드백
내가 목표하는 회사의 공모를 잘 보고 캠프 기간을 이어가자 -> 원하는 회사별 도메인의 지식을 추가로 알아보자
7조
우리조
일단 망함
발표자 컴퓨터 사양 부족으로 렉도 걸리고 화면 공유도 잘못했음
다른 조들과 다른 정보를 찾아봄 -> 신박하나 의미가 있었을까? 조금 아쉽다
자료가 부족하나 하나하나 듣기 편하고 이해가 잘됨
다른 조와 다른 점들이 있었다 데이터는 동일하다 데이터 사이언티스트가 데이터를 QAQC에게 얻어 각자 분석을 함 업무적
결국 하는 일은 비슷함 -> 발표 자료와 비슷했다 ~
뒷 부분 갈수록 데이터가 들어가서 좋았음 긴장을해서 인공지능 얘기보단 요즘 AI ALM 챗GPT같은걸 기재해서 얘기했으면 더 좋았겠다 AI도 50년대부터 있긴 했음 /// 연봉은 블라인드 회사별로 회사별 연봉 공유한 시트가 있음 자료 신뢰성 높은거임 // 제조
4조
정말 잘함
현실을 직시할 수 있는 커리어 스터디
공고를 올려놔 좋았음
수치적인 시리얼데이터 <-> 이미지데이터 좀 다름 가고 싶은 회사의 도메인은 중점적인게 무엇인지
의사소통 !! 이 많이 중요하다~ 툴을 아는것도 중요함 // 실시간 데이터 처리 듣기 좋았다
'본 캠프 TIL' 카테고리의 다른 글
| 12월24일 TIL (1) | 2024.12.24 |
|---|---|
| 12월23일 TIL (4) | 2024.12.23 |
| 12월 18일 TIL (6) | 2024.12.18 |
| 12월 17일 TIL (4) | 2024.12.17 |
| 12월 16일 TIL (2) | 2024.12.16 |