데이터분석파이썬 5주차
01. 파일 불러오기 및 저장하기
- 1) 파일 확장자
- CSV 파일 (.csv)
- CSV 파일은 Comma Separated Values의 약자로, 데이터를 쉼표(,)로 구분하여 저장하는 형식입니다.
- Excel 파일 (.xls, .xlsx)
- Excel 파일은 표 형태로 데이터를 저장하는 Microsoft Excel의 형식입니다.
- JSON 파일 (.json) (간단하게 데이터 적재되어 있음 / 용량 적고 효과적으로 저장 가능)
- JSON 파일은 JavaScript Object Notation의 약자로, 데이터를 저장하는 간단한 형식입니다.
- 텍스트 파일 (.txt, .dat, 등)
- 텍스트 파일은 일반 텍스트로 된 데이터를 저장하는 파일입니다.
- CSV 파일 (.csv)
- 2) 확장자에 따른 파일 불러오는 함수
- CSV 파일 (.csv)
- 데이터프레임으로 불러오기: pandas 라이브러리의 read_csv() 함수를 사용합니다.
- (아래 코드들은 예시로 임의의 파일제목을 작성하였는데 실제로는 없는 파일이므로 실제 실행이 되지는 않습니다! 참고용으로 봐주세요!)
- CSV 파일 (.csv)
import pandas as pd
df = pd.read_csv('file.csv') *****file.csv : 파일 경로
- Excel 파일 (.xls, .xlsx)
- 데이터프레임으로 불러오기: **pandas**의 read_excel() 함수를 사용합니다.
import pandas as pd
df = pd.read_excel('file.xlsx')
- JSON 파일 (.json)
- 데이터프레임으로 불러오기: **pandas**의 read_json() 함수를 사용합니다.
import pandas as pd
df = pd.read_json('file.json')
- 텍스트 파일 (.txt, .dat, 등)
- 데이터프레임으로 불러오기: **pandas**의 read_csv() 함수를 사용할 수 있습니다.
import pandas as pd
df = pd.read_csv('file.txt', delimiter='\t') # 만약 데이터가 탭(\)으로 구분되어 있다면 delimiter='\t'를 사용합니다.
- 위 예시들은 주로 pandas 라이브러리를 사용하여 데이터를 불러오는 방법을 보여줍니다.
- **pandas**는 파이썬 데이터 분석에서 매우 효과적으로 사용되는 라이브러리이며, 데이터프레임 형태로 데이터를 다루기에 매우 편리합니다.
- 이러한 파일 포맷과 불러오는 방법에 대한 이해는 파이썬 데이터 분석가로서의 기본적인 지식 중 하나입니다.
- 3) 파일 저장하기
- CSV 파일 (.csv)
import pandas as pd
data = {
'Name': ['John', 'Emily', 'Michael'],
'Age': [30, 25, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
excel_file_path = '/content/sample_data/data.csv'
df.to_csv(excel_file_path, index = False) ******index를 False라고 해주면
print("csv 파일이 생성되었습니다.")

Excel 파일 (.xls, .xlsx)
import pandas as pd
data = {
'Name': ['John', 'Emily', 'Michael'],
'Age': [30, 25, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
excel_file_path = '/content/sample_data/data.xlsx'
df.to_excel(excel_file_path, index = False)
print("Excel 파일이 생성되었습니다.")
JSON 파일 (.json)
import json
data = {
'Name': ['John', 'Emily', 'Michael'],
'Age': [30, 25, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
json_file_path = '/content/sample_data/data.json'
# json 파일을 쓰기모드(w키)로 열어서 data를 거기에 덮어씌우게 됩니다.
with open(json_file_path, 'w') as jsonfile:
json.dump(data, jsonfile, indent=4)
print("JSON 파일이 생성되었습니다.")
*with를 쓰는 이유는 안쓰게되면 재이슨 파일을 한번 열었기 때문에 반드시 닫는 코드도 작성해야하는데 with문이 끝날 때 자동으로 닫아줘서(알필요x)
**dump 데이터를 재이슨 파일에 덮어 씌우는데 쓰임
텍스트 파일 (.txt, .dat, 등)
data = {
'Name': ['John', 'Emily', 'Michael'],
'Age': [30, 25, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
text_file_path = '/content/sample_data/data.txt'
with open(text_file_path, 'w') as textfile:
for key, item in data.items():
textfile.write(str(key) + " : " + str(item) + '\n')
print("텍스트 파일이 생성되었습니다.")
* " : " 안넣어도 됨
** '\n' 한줄 띄운다
***
02. 패키지(라이브러리) 사용하기
- 1) 패키지란?
- 패키지는 관련된 여러 개의 모듈을 포함하는 디렉토리입니다.
- 패키지 안에는 일반적으로 라이브러리나 다른 패키지가 포함될 수 있습니다.
- 예를 들어, **numpy**와 **matplotlib**는 여러 모듈을 포함하는 패키지입니다.
- 데이터 분석을 위한 파이썬 패키지들은 다양한 작업을 수행하는 데 필수적입니다.
- 이들 패키지들은 데이터 수집, 전처리, 시각화, 모델링, 통계 분석 등 다양한 기능을 제공합니다.
- 파이썬에서 패키지와 라이브러리를 사용하는 것은 코드의 재사용성을 높이고, 개발 속도를 빠르게 하며, 코드의 가독성을 향상시킵니다.
- 또한, 다른 개발자들이 작성한 코드를 활용함으로써 자신의 프로젝트를 보다 효율적으로 개발할 수 있습니다.
- 패키지는 맨 처음 파이썬을 사용할 때 필요한 패키지들을 맨 위에 한번에 불러놓고 사용하면 편리해요!
# 아래와 같이 보통은 필요한 패키지를 한번에 다 불러온 다음 코딩을 진행합니다
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn
- 2) 다양한 종류의 패키지
- pandas
- 데이터 조작과 분석을 위한 라이브러리로, 데이터를 효과적으로 조작하고 분석할 수 있도록 도와줍니다.
- 아래 코드는 현재 파일이 없는 상황이므로 실행이 되지 않는게 맞습니다.
- 데이터 조작과 분석을 위한 라이브러리로, 데이터를 효과적으로 조작하고 분석할 수 있도록 도와줍니다.
- pandas
import pandas as pd
df = pd.read_excel(file_address)
print(df)
- numpy
- 과학적 계산을 위한 핵심 라이브러리로, 다차원 배열과 행렬 연산을 지원합니다.
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(arr.mean())
- matplotlib
- 데이터 시각화를 위한 라이브러리로, 다양한 그래프와 플롯을 생성할 수 있습니다.
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show()
- seaborn
- Matplotlib을 기반으로 한 통계용 데이터 시각화 라이브러리로, 보다 간편하고 아름다운 시각화를 제공합니다.
import seaborn as sns
import pandas as pd
data_sample = pd.DataFrame({'x':[1, 2, 3, 4], 'y':[1, 4, 9, 16]})
sns.barplot(data=data_sample, x='x', y='y')
- scikit-learn (머신러닝 쓸 때 가장 많이 쓰임)
- 머신 러닝 알고리즘을 사용할 수 있는 라이브러리로, 분류, 회귀, 군집화, 차원 축소 등 다양한 머신 러닝 기법을 제공합니다.
from sklearn.datasets import load_iris
from sklearn.linear_model import LinearRegression
# Iris 데이터셋 불러오기
iris = load_iris()
# Iris 데이터셋에서 특정 범위의 데이터 슬라이싱하기
X_train = iris.data[:,:-1] # 데이터 값들 추출
print("학습 데이터:", X_train)
y_train = iris.data[:,-1:] # 정답값 추출
print("학습 데이터:", y_train)
model = LinearRegression()
model.fit(X_train, y_train)
- statsmodels (많이 쓰이진 않음)
- 통계 분석을 위한 라이브러리로, 회귀 분석, 시계열 분석, 비모수 통계 등 다양한 통계 기법을 제공합니다.
import statsmodels.api as sm
model = sm.OLS(y_train, X_train)
result = model.fit()
print(result.summary())
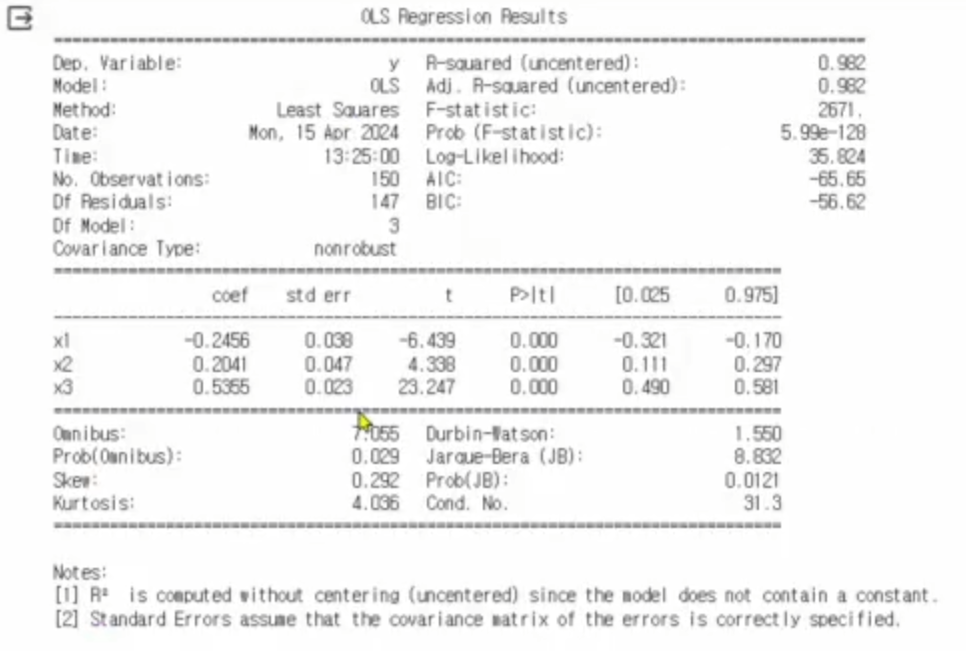
- scipy
- 과학기술 및 수학적인 연산을 위한 라이브러리로, 다양한 과학 및 공학 분야에서 활용됩니다. 선형대수, 최적화, 신호 처리, 통계 분석 등 다양한 기능을 제공합니다.
import numpy as np
from scipy.integrate import quad
# 적분할 함수 정의
def integrand(x):
return np.exp(-x ** 2)
# 정적분 구간
a = 0
b = np.inf
# 적분 계산
result, error = quad(integrand, a, b)
print("결과:", result)
print("오차:", error)
- tensorflow (명실상부한 딥러닝 패키지/라이브러리,최근 2버전으로 개정되면서 기업에서 자주 쓰임)
- 딥러닝 및 기계 학습을 위한 오픈소스 라이브러리로, 구글에서 개발했습니다. 그래프 기반의 계산을 통해 수치 계산을 수행하며, 신경망을 구축하고 학습할 수 있습니다.
import tensorflow as tf
input_size = 3
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(input_size,)),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
- pytorch (명실상부한 딥러닝 패키지/라이브러리, 연구용으로 자주 쓰임)
- 딥러닝을 위한 오픈소스 라이브러리로, Facebook에서 개발했습니다. 동적 계산 그래프를 사용하여 신경망을 구축하고 학습할 수 있습니다.
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
- 위의 패키지들은 각각 고유한 기능과 장점을 가지고 있으며, 데이터 분석 및 머신 러닝, 딥러닝 작업을 위해 널리 사용됩니다.
- 데이터 분석 프로젝트나 머신 러닝/딥러닝 모델 구축 시에는 데이터의 특성과 목표에 맞게 적절한 패키지를 선택하여 활용하는 것이 중요합니다.
03. 포맷팅(formatting) 사용하기
- 포맷팅이란? : 변수와 문자를 다양하게 출력할 때 아주 쉽게 코드를 짜게해주는 이쁜이
- 저번 시간 출력문에 대해서 배울 때 print 함수에 대해서 배웠어요!
- 이번에는 이를 활용한 조금 더 세련된 기술을 써 보도록 해요 ㅎㅎ
- 문자와 변수를 함께 출력할 때 위와 같이 콤마(,)와 함께 써도 되지만 포맷팅(formatting)이라는 문법을 사용해볼 수 있어요!
- 포맷팅 문법도 여러개가 있는제 그 중 요즘 많이 사용하는 f-string을 활용하는 방법을 먼저 알려드릴게요!
- 코드가 아주 직관적으로 바뀌며 변수와 문자가 다양하게 많이 출력해야 하는 상황에서 훨씬 편리하게 사용할 수 있어요!!
- 아래와 같이 포맷팅 문법을 활용하여 문자열과 변수를 함께 출력해봅시다.
x = 10
print(f"변수 x의 값은 {x}입니다.") : f"를 기재함으로써 포맷팅 시작 선언 , {x} 내가 넣고 싶은 변수에 중괄호(f-str방법)
- 콤마(,)를 활용한 방법이랑 비교해보니 어떤가요~? 여러번 콤마(,)를 찍을 필요가 없고 코드가 훨씬 깔끔하지 않나요? ㅎㅎ
- f-string 포맷팅을 사용하려면 문자열 맨 앞에 f를 집어 넣고 내가 놓고자 하는 **변수의 위치에 중괄호{}**를 사용하여 변수와 함께 기입하면 됩니다
- 포맷팅 분법 (특히, f-string)은 다양한 상황에서 아주 많이 사용하기 때문에 꼭 기억해 놓으시길 추천 드립니다 🙂
- 물론, 다른 포맷팅 방법도 두 가지 더 있어요!
- 위 방법만 써도 상관 없지만 간혹 다른 사람의 코드를 읽을 때 필요할 수도 있으니 한번 봐 두도록 합시다!
x = 10
print("변수 x의 값은 {}입니다.".format(x)) *****옛날 방식 (구~식)
- 위 방법은 어떤가요? 비슷하긴 한데 조금 다르죠?
- 문자열 맨 앞에 f를 적을 필요는 없고 변수의 위치에 중괄호{}를 넣는 건 f-string 방법이랑 똑같애요.
- 하지만, 문자열 맨 뒤에 온점(.)을 찍고 format() 함수를 사용하며 그 함수에 변수를 집어 넣어주어야 해요!
- 여러분은 어느 것이 더 편하신가요? 저는 개인적으로 f-string이 편하지만 이는 사람마다 다를 수 있기 때문에 본인이 편하신 걸로 아무거나 사용해도 됩니다!
- 다만, 다른 사람의 코드를 봐야 하는 상황도 종종 있으니 다양한 방법들을 알고 있으면 좋아요 🙂
- 마지막으로, 포맷팅 방법이 하나 더 있습니다!
- 이번에 소개드릴 방법은 옛날 방식의 포맷팅인데 (그래서 별로 추천하지는 않습니다..ㅎ) 조금 귀찮은 작업이 많습니다.
- 권장하는 방식은 아니지만 위에선 언급한데로 다른 사람의 코드를 볼 때 (특히 옛날 코드를 보거나 기존 습관을 버리지 못한 사람의 코드를 볼 때) 필요할 수도 있으니 알아 두도록 합시다!
- 아래와 같이 포맷팅을 해보도록 합시다
x = 10
print("변수 x의 값은 %d입니다." % (x)) ***찐 옛날 방식 (개구~식)
- 이 방법은 어떤가요~? 변수를 넣을 위치에 %라는 새로운 기호를 쓸 뿐만 아니라 어느 타입의 변수를 넣을 것인지(숫자는 d, 문자는 s)도 써 주어야 합니다.
- 뿐만 아니라, 문자열 맨 끝에 %를 작성한 다음 괄호()안에 변수를 작성해줘야 해요!
- 확실히 위 두 방법에 비해서 조금 신경써야 할게 많죠~? 그래도 이 방법을 쓰고 싶으시다면 말리지는 않겠습니다 어떤 방법을 쓰든 결국 자신한테 편한 방법을 찾으면 됩니다 🙂
다른 예시로 한 번 더 3 가지 방법의 포맷팅을 해보면서 포맷팅을 이해하고 마무리 하도록 해요 🙂
name = "Alice"
age = 25
# %를 사용한 형식 지정
print("이름: %s, 나이: %d세" % (name, age))
# format() 메서드를 사용한 형식 지정
print("이름: {}, 나이: {}세".format(name, age))
# f-string을 사용한 형식 지정 ****Python 3.6 이상만 가능
print(f"이름: {name}, 나이: {age}세")
이름: Alice, 나이: 25세
이름: Alice, 나이: 25세
이름: Alice, 나이: 25세
- 2) 실전에서 사용되는 예시1 : 데이터 분석 결과물 출력 (변수가 변해도 틀이 그대로라 문제없음)
- 이번에는 위에서 배운 것을 토대로 실제 데이터 분석 상황에서 사용될 법한 예시를 다루어 보도록 해요!
- 아래와 같이 데이터 분석 결과를 설명과 함께 출력해 보는 코드를 짜 보도록 해요 🙂
# 데이터 분석 결과
num_records = 1000
avg_age = 35.6
median_income = 50000
# 출력 포맷 지정
output_string = f"총 {num_records}명의 레코드가 분석되었습니다. 평균 나이는 {avg_age}세이며, 중위 소득은 {median_income}입니다."
# 결과 출력
print(output_string)
- 3) 실전에서 사용되는 예시2 : AI 모델의 정확도 출력
- 이번에는 AI 모델의 결과를 출력하는 상황의 예시를 다루어 보도록 해요!
- 아쉽게도 파이썬 문법 단계에서는 AI모델의 코드를 다루지는 않을 거에요! 따라서, AI모델의 결과가 accuracy라는 변수에 담겨졌다고 가정하고 그 결과를 출력해 보도록 할게요!
- 아래와 같이 데이터 분석 결과를 설명과 함께 출력해 보는 코드를 짜 보도록 해요 🙂
# 딥러닝 모델의 정확도
accuracy = 0.8765
# 지금은 숫자가 바로 들어갔지만 실전에선 AI의 모델의 결과들을 가지고 따로 계산해서 얻어냅니다.
# 출력 포맷 지정
output_string = f"모델의 정확도는 {accuracy}입니다."
# 결과 출력
print(output_string)
04. 리스트 캄프리헨션
- 1) 리스트 캄프리헨션이란? (안써도 되긴 하는데 반복문이랑 조건문을 리스트 안에 한번에 쓸 수 있음)
- 리스트 캄프리헨션은 파이썬에서 리스트를 간결하게 생성하는 방법 중 하나입니다.
- 보통 반복문과 조건문을 사용하여 리스트를 생성할 때 사용됩니다.
- 이는 코드를 더 간결하고 가독성 있게 만들어 줍니다.
- 리스트 캄프리헨션은 파이썬의 강력한 기능 중 하나로, 데이터 처리 및 변환에 유용하게 활용됩니다.
- 기본적인 구조는 아래와 같습니다.
# 기본적인 구조
[표현식 for 항목 in iterable if 조건문]
*표현식 : 계산/방법등
** for 항목 in iterable : 반복
*** if 조건문 : 조건 필요없으면 빼도 됨
2) 리스트 캄프리헨션 예제
# 예시: 1부터 10까지의 숫자를 제곱한 리스트 생성
squares = [x**2 for x in range(1, 11)]
print(squares) # 출력: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
*반복문이면? (길다~ -> 적당히 이해하고 쓸줄 알아라~ 굳이 안쓰고 싶다면 쓰지 않아도 좋다~ 난 좀 헷갈린다 ㅇㅇ)
squares = []
for x in range(1,11):
squares.append(x**2)
print(squares)
# 예시: 리스트에서 짝수만 선택하여 제곱한 리스트 생성
even_squares = [x**2 for x in range(1, 11) if x % 2 == 0]
print(even_squares) # 출력: [4, 16, 36, 64, 100]
# 예시: 문자열 리스트에서 각 문자열의 길이를 저장한 리스트 생성
words = ["apple", "banana", "grape", "orange"]
word_lengths = [len(word) for word in words]
print(word_lengths) # 출력: [5, 6, 5, 6]
# 예시: 리스트 컴프리헨션을 중첩하여 2차원 리스트 생성
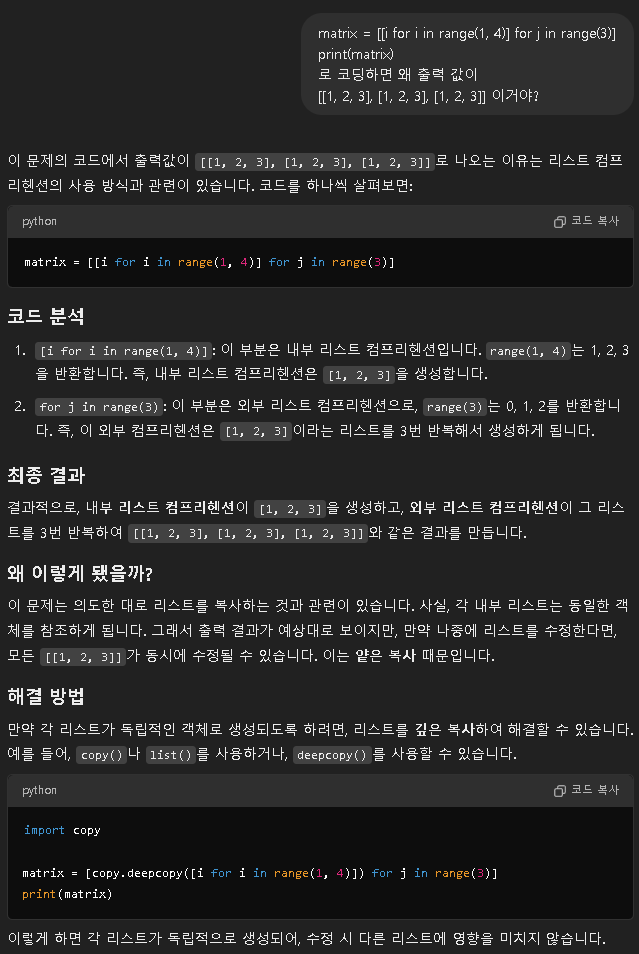
matrix = [[i for i in range(1, 4)] for j in range(3)]
print(matrix) # 출력: [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
★AI 괴롭히기
# 리스트 컴프리헨션 중첩
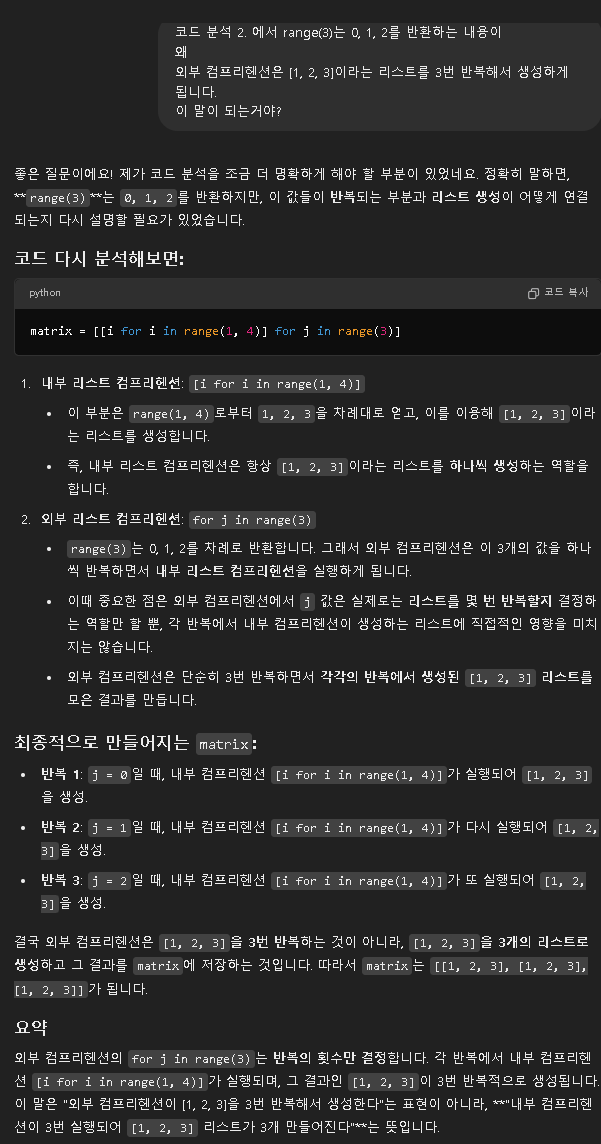
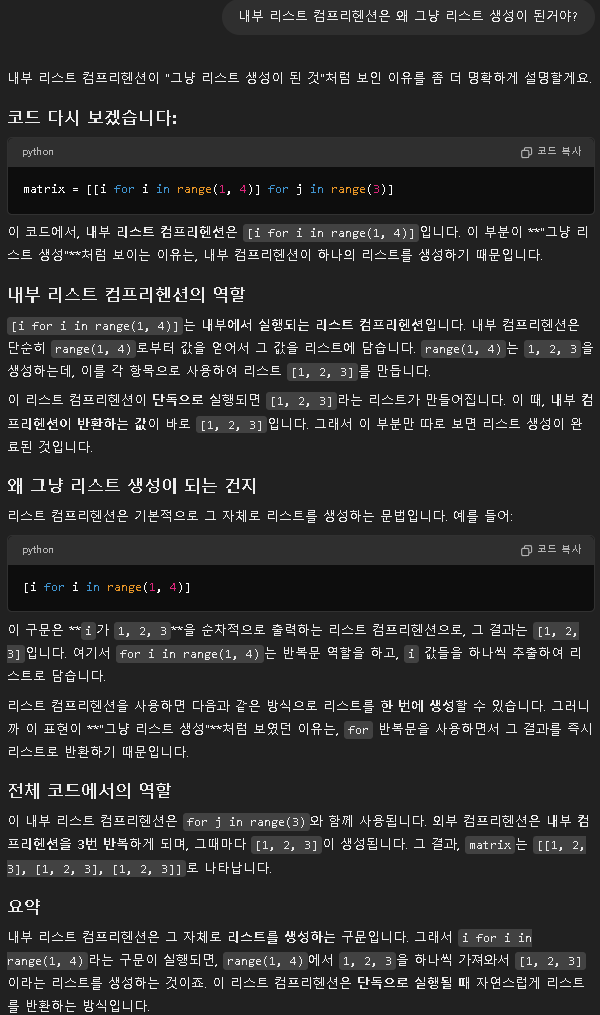
matrix = [[i for i in range(1, 4)] for j in range(3)]
print(matrix)
결론 :
리스트 캄프리헨션은 기본적으로 그자체로 리스트를 만드는 문법임
내부 캄프리헨션을 하면 야랄할거 없이 그냥 [1 , 2 ,3 ]으로 리스트만 만들어짐
외부 캄프리헨션을 하면 야랄할거 있어서 [1 , 2 ,3 ]를 [0, 1, 2]에 한번씩 야랄함 그
결과 [ [1 , 2 ,3 ], [1 , 2 ,3 ], [1 , 2 ,3 ]]라는 요상한 결과값이 만들어짐 ㅇㅋ? ㅇㅋ
- 위 예시에서 **표현식**은 각 항목에 대한 계산이나 변환을 의미하고, **항목**은 반복되는 값이며, **iterable**은 반복 가능한 객체입니다.
- **if 조건문**은 선택적으로 사용될 수 있으며, 조건이 참일 때만 해당 항목을 결과 리스트에 추가합니다.
- 리스트 캄프리헨션은 루프문과 비교했을 때 코드가 간결하고 가독성이 좋으며, 데이터 처리 및 변환 작업을 더 효율적으로 수행할 수 있도록 도와줍니다.
05. lambda 사용하기
- 1) lambda(람다)란? (굳이 안써도됨)
- 람다 함수(lambda function)는 익명 함수로, 이름 없이 정의되는 간단한 함수입니다.
- 주로 한 줄로 표현되며, 일반적인 함수 정의와는 달리 def 키워드를 사용하지 않고 lambda 키워드를 사용하여 정의됩니다.
- 람다 함수는 주로 함수를 매개변수로 전달하는 함수형 프로그래밍에서 유용하게 활용됩니다.
아래 내용들을 통해 람다 함수의 기본 구조와 예시를 살펴보도록 합시다.
- 2) lambda와 함수의 차이점
- 정의 방식
- 일반 함수는 def 키워드를 사용하여 명시적으로 함수를 정의합니다.
- 람다 함수는 lambda 키워드를 사용하여 익명 함수를 간단히 정의합니다.
- 구조
- 일반 함수는 여러 줄의 코드 블록을 가질 수 있습니다.
- 람다 함수는 주로 한 줄로 표현되는 간단한 표현식만을 포함합니다.
- 이름
- 일반 함수는 함수의 이름을 지정하여 호출할 수 있습니다.
- 람다 함수는 이름이 없기 때문에 한 번만 사용되거나 임시로 필요한 경우에 사용됩니다.
- 사용
- 일반 함수는 어떤 경우에도 사용할 수 있습니다.
- 람다 함수는 주로 함수를 매개변수로 받거나 함수를 반환하는 고차 함수, 즉 함수형 프로그래밍에서 사용됩니다.
- 정의 방식
- 3) lambda를 쓰는 이유
- 간결성
- 람다 함수는 코드를 더 간결하게 만들어 줍니다. 특히 간단한 연산이나 조작이 필요한 경우에 유용합니다.
- 익명성
- 이름이 없기 때문에 임시로 필요한 경우에 사용할 수 있습니다. 예를 들어, 정렬이나 필터링과 같은 함수의 매개변수로 전달할 때 많이 사용됩니다.
- 함수형 프로그래밍
- 함수를 값으로 취급하고 함수를 다루는 함수형 프로그래밍 패러다임에서 람다 함수가 필요합니다. 이러한 경우에는 함수를 매개변수로 받는 고차 함수를 작성하거나 함수를 반환하는 경우에 람다 함수가 효과적으로 사용됩니다.
- 가독성
- 람다 함수는 간단한 표현식을 사용하여 코드를 작성하므로 가독성이 향상될 수 있습니다. 특히 함수가 짧고 명확한 경우에 유용합니다.
- 그러나 람다 함수는 모든 상황에 적합하지는 않습니다.
- 복잡한 기능을 가진 함수나 여러 줄의 코드가 필요한 경우에는 일반 함수를 사용하는 것이 좋습니다.
- 종종 람다 함수는 코드를 간결하게 만들어주고 함수형 프로그래밍에서 유용한 도구로 활용됩니다.
- 간결성
- 4) lambda 함수의 예시
간단한 덧셈 함수
add = lambda x, y: x + y
print(add(3, 5)) # 출력: 8
def x_y_cal(x,y):
return x+y
단, 파이썬 함수는 라이브러리 불러올 때 사용할 함수도 정의를 해놓는데 , 람다는 중간중간 마다 사용해 수정이 용이함
파이썬 적으론 def 형식이 맞으나 데이터 분석가 측면에선 람다가 좋다
제곱 함수
square = lambda x: x ** 2
print(square(4)) # 출력: 16
- 리스트의 요소 중 짝수만 필터링
- 참고!) filter 라는 내장함수는 여러 개의 데이터로부터 조건을 충족하는 데이터만 추출할 때 사용하는 함수
filter(조건 함수, 반복 가능한 데이터)
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 출력: [2, 4, 6, 8, 10]
- 리스트의 각 요소에 대한 제곱 (필터는 조건대로 추출 / 맵은 함수대로 만들어줌)
- 참고!) map 이라는 내장함수는 여러개의 값을 받아서 각각의 값에 함수를 적용한 결과를 반환한 내장함수
map(함수, 반복 가능한 데이터)
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x ** 2, numbers))
print(squared_numbers) # 출력: [1, 4, 9, 16, 25]
- 람다 함수는 간단한 함수를 정의하고자 할 때 특히 유용합니다.
- 과도하게 사용하면 코드의 가독성을 해치므로 적절히 활용하는 것이 좋습니다.
- 하지만! 간단한 수식을 사용하는 경우 아주 유용하기 때문에 데이터 분석 관점에서는 알아두면 좋은 문법 입니다 🙂
06. glob 사용하기
- 1) glob란? (데이터 경로에 파일들이 어떤 것이 있는지 데이터 다룰 때 유용히 쓰임)
- glob 함수는 파일 시스템에서 파일을 찾을 때 사용되는 유용한 도구입니다.
- 이 함수는 파일 이름의 패턴 매칭을 통해 파일을 검색하고, 일치하는 파일들의 리스트를 반환합니다.
- 주로 파일 이름이나 확장자에 따라 파일을 필터링하는 데 사용됩니다.
- glob 함수의 사용법
- 참고!) 폴더(디렉토리)에 대한 유용한 개념들!
- 폴더를 구분할때는 ‘/’기호를 사용하면 됩니다!
- 파일명을 입력해줄 때 반드시 확장자도 함께 입력해주어야 합니다!
- 일치하는 파일이나 디렉토리의 패턴을 나타낼 때 와일드카드 문자를 사용됩니다. 주로 파일이나 디렉토리의 이름을 검색하거나 일괄적으로 처리할 때 유용하게 사용됩니다.
- *** : 0개 이상의 모든 문자와 일치합니다.**
- *ex) .txt : 해당 디렉토리에서 텍스트파일 모두 해당
- 그밖의 와일드카드 문자로 ?, [], {} 등이 있습니다.
- [] : 대괄호 안에 포함된 문자 중 하나와 일치합니다.
- {} : 중괄호 안에 포함된 문자열 중 하나와 일치합니다.
- *** : 0개 이상의 모든 문자와 일치합니다.**
- 참고!) 폴더(디렉토리)에 대한 유용한 개념들!
import glob
# 현재 경로의 모든 파일을 찾기 *** 확장자 있으면 파일 / 없으면 폴더
file_list1 = glob.glob('*')
# 단일 파일 패턴으로 파일을 찾기 ***드라이브가 있는 파일만 찾기
file_list2 = glob.glob('drive')
# 디렉토리 안의 모든 파일 찾기 *** 샘플 데이터 폴더 안에 있는 모든 파일을 확인할 때
file_list3 = glob.glob('sample_data/*')
# 특정 확장자를 가진 파일만 찾기 *** 샘플 데이터 폴더 안에 확장자가 csv인 파일을 찾을 때
file_list4 = glob.glob('sample_data/*.csv')
*glob 함수를 사용하면 특정 패턴에 맞는 파일을 간단하게 찾을 수 있습니다. 이는 파일 시스템에서 파일을 검색하고 처리하는 데 유용합니다.
ex)
tmp = []
for file_address in file_list5:
df = pd.read_csv(file_address)
tmp.append(df)
07. os 사용하기
- 1) os란?
- os 모듈은 운영 체제와 상호 작용하기 위한 다양한 함수들을 제공합니다.
- 이 모듈은 파일 시스템을 관리하고, 디렉토리를 탐색하고, 파일을 조작하는 데 사용됩니다.
- 아래에는 os 모듈의 주요 기능과 예시를 제공합니다.
- 주요 기능
- 파일 및 디렉토리 관리:
- 파일 생성, 이름 변경, 삭제 등의 작업을 수행할 수 있습니다.
- 디렉토리 생성, 탐색, 삭제 등의 작업을 수행할 수 있습니다.
- 경로 관리:
- 절대 경로, 상대 경로, 현재 작업 디렉토리 등의 경로를 관리할 수 있습니다.
- 경로 구성 요소를 조작하고, 경로를 연결하고, 경로를 정규화할 수 있습니다.
- 환경 변수 관리:
- 시스템의 환경 변수를 가져오거나 설정할 수 있습니다.
- 실행 관리:
- 외부 프로그램을 실행하거나, 현재 프로세스의 종료 등의 작업을 수행할 수 있습니다.
- 파일 및 디렉토리 관리:
- 2) os를 사용하는 예시
- 파일 및 디렉토리 관리:
현재 작업 디렉토리 가져오기
import os
cwd = os.getcwd()
print(cwd)
디렉토리 생성
import os
os.mkdir('sample_data/new_directory')
파일 이름 변경
import os
os.rename('sample_data/new_directory', 'sample_data/new_directory2')
파일 삭제
맨 위에서 ‘파일 불러오기’를 진행했을 때 우리가 드라이브에 넣어주었던 엑셀 파일을 한번 지워보도록 해요!
import os
os.remove(file_adress)
import os
os.remove('sample_data/data.csv')
경로 관리:
1) 파일 목록(경로) 가져오기 (글로브와 다른 점은 os의 경우 숨겨진 파일까지 볼 수 있음)
import os
files = os.listdir('/content')
print(files)
2) 경로 조작 (파일 경로를 이어서 만들 때)
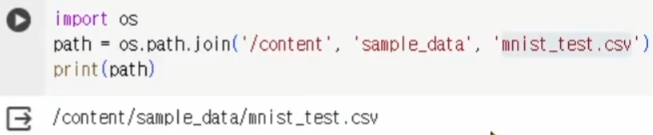
import os
path = os.path.join('/content', 'sample_data', 'mnist_test.csv')
print(path)
08. split 사용하기
- split란? *** 파일을 다룰 때 많이 쓰이는데 파일 경로가 / / 로 구분되는데 스플리트 쓰면 각각 구분이 되서 폴더명,파일명 구분에 유리함 (glob, map, split 전부 다 데이터 다룰 때 자주 쓰임)
- 리스트의 split 메서드를 활용하면 문자열을 여러개로 쪼개는데 유용해요.
- 이러한 메서드를 알고 있으면 문자열로 되어 있는 파일 경로로 부터 파일 제목을 추출하는 등의 상황에서 아주 유용하게 사용할 수 있습니다!
- 문자열을 공백 기준으로 분할하여 리스트로 변환하기
sentence = "Hello, how are you doing today?"
words = sentence.split()
print(words) # 출력: ['Hello,', 'how', 'are', 'you', 'doing', 'today?']
**** .split() 아무것도 안넣으면 공백에 따라 나눠서 리스트에 지정해줌
특정 구분자를 기준으로 문자열을 분할하여 리스트로 변환하기
data = "apple,banana,grape,orange"
fruits = data.split(',')
print(fruits) # 출력: ['apple', 'banana', 'grape', 'orange']
리스트의 각 항목을 문자열로 결합하기 (split 메서드는 아니지만 함께 알아두도록 해요!)
words = ['Hello', 'how', 'are', 'you', 'doing', 'today?']
sentence = ' '.join(words)
print(sentence) # 출력: Hello, how are you doing today?
** ''형식을 조인해 줄건데 한칸씩 띄워서 ' ' 조인(합)한다
리스트의 각 항목을 문자열로 결합하되, 특정 구분자를 사용하여 결합하기
fruits = ['apple', 'banana', 'grape', 'orange']
data = ','.join(fruits)
print(data) # 출력: apple,banana,grape,orange
** ,별로 조인할거라 ','
여러 줄로 이루어진 문자열을 줄 단위로 분할하여 리스트로 변환하기
text = """First line
Second line
Third line"""
lines = text.split('\n')
print(lines) # 출력: ['First line', 'Second line', 'Third line']
***\n 한칸 띄운다
문자열에서 공백을 제거한 후 문자열을 리스트로 변환하기 (유사 슬라이싱)
text = " Hello how are you "
cleaned_text = text.strip()
words = cleaned_text.split()
print(words) # 출력: ['Hello', 'how', 'are', 'you']
*** .strip() 글자 양 옆의 공백 제거
- split가 실전에서 사용되는 예시1 : 데이터 불러올때 경로 처리할때 split 사용
- 아래의 예시에서는 **file_path**라는 문자열 변수에 데이터의 경로를 저장하고, split() 함수를 사용하여 문자열을 / 기준으로 분할합니다.
- 이때, rsplit() 함수를 사용하여 오른쪽에서부터 최대 1회만 분할하도록 설정하여 파일명과 디렉토리로 나눕니다.
- 분할된 결과를 각각 **directory**와 filename 변수에 할당하여 출력합니다.
# 데이터의 경로를 문자열로 표현
file_path = "/usr/local/data/sample.txt"
# split() 함수를 사용하여 디렉토리와 파일명으로 분할
directory, filename = file_path.rsplit('/', 1)
print("디렉토리:", directory) # 출력: 디렉토리: /usr/local/data
print("파일명:", filename) # 출력: 파일명: sample.txt
**이러한 방식으로 데이터의 경로를 문자열로 표현하고, 이를 split() 함수를 활용하여 필요한 정보를 추출 가능
*** rsplit(' ', 1) 오른쪽에서 첫번째 문자까지 구분

09. 클래스 배우기
- 1) 클래스란? (함수가 많아지면 관리하기 어려움 / 클래스 사용 시 비슷한 함수끼리 묶어줄 수 있음)
- 파이썬 클래스(Class)는 객체 지향 프로그래밍(OOP)의 중요한 개념 중 하나입니다.
- 객체 지향 프로그래밍은 현실 세계의 사물을 모델링하여 프로그래밍하는 방법으로, 이를 통해 코드의 재사용성과 유지보수성을 향상시킬 수 있습니다.
- 이 강의에서는 파이썬 클래스의 기본적인 개념부터 시작하여 다양한 코드 예시를 통해 설명하겠습니다.
- 클래스(Class)의 기본 구조
- 파이썬에서 클래스는 다음과 같은 형태로 정의됩니다.
* 객체 지향 프로그래밍(OOP) : 현실 세계의 사물을 모델링하여 프로그래밍한 방법(=>사람이 쓰기 편한)
class ClassName:
def __init__(self, parameter1, parameter2): ** self를 매개변수로 무조건 넣어줘야함 -> 클래스 특징
self.attribute1 = parameter1 *** def 어쩌구 다~ 메서드다
self.attribute2 = parameter2 ***** 이거 3줄은 불변
def method1(self, parameter1, parameter2): ***메서드
# 메서드 내용 작성
pass
- 여기서 __init__ 메서드는 클래스의 생성자로, 객체가 생성될 때 호출되며 초기화 작업을 수행합니다.
- 클래스 내부의 메서드들은 클래스의 동작을 정의하는 함수입니다.
- 메서드의 첫 번째 매개변수로 self를 반드시 사용해야 합니다. 이는 해당 메서드가 속한 객체를 가리킵니다.
- 클래스와 객체(Object)의 관계
- 클래스는 객체를 만들기 위한 틀 또는 설계도입니다. 객체는 이러한 클래스를 이용하여 생성됩니다.
- 예를 들어, Person 클래스를 정의하면 이 클래스를 사용하여 여러 사람 객체를 만들 수 있습니다.
class Person:
def __init__(self, name, age): ***메서드
self.name = name
self.age = age
# 객체 생성
person1 = Person("Alice", 30)
person2 = Person("Bob", 25)
- 다형성(Polymorphism)
- 다형성은 같은 이름의 메서드가 서로 다른 클래스에서 다른 기능을 수행하도록 하는 개념입니다.
class Animal:
def sound(self):
print("Some generic sound")
class Dog(Animal):
def sound(self):
print("Woof")
class Cat(Animal):
def sound(self):
print("Meow")
# 다형성 활용
animals = [Dog(), Cat()]
for animal in animals:
animal.sound()
* 위 코드에서 Animal 클래스의 sound 메서드를 각각의 하위 클래스인 Dog와 Cat에서 재정의하여 다른 동작을 수행
- 2) 클래스와 함수의 차이점
- 클래스와 함수는 모두 파이썬에서 코드를 조직화하고 재사용성을 높이는 데 사용됩니다. (클래스가 더 높음)
- 그러나 클래스와 함수는 목적과 사용 방법에서 차이가 있습니다.
- 함수(Function)
- 함수는 일련의 작업을 수행하는 블록입니다.
- 함수는 일반적으로 입력(매개변수)을 받아들이고 그에 따른 결과를 반환합니다.
- 함수는 특정한 작업을 수행하는 독립적인 코드 블록으로, 재사용성을 높이고 코드의 가독성을 개선합니다.
- 함수는 클래스와 상관없이 독립적으로 정의될 수 있습니다.
- 클래스(Class)
- 클래스는 데이터와 해당 데이터를 처리하는 메서드(함수)를 함께 묶어놓은 것입니다.
- 클래스는 객체 지향 프로그래밍의 핵심 개념으로, 데이터와 데이터를 다루는 코드를 함께 묶어 객체를 생성할 수 있게 합니다.
- 클래스는 객체의 상태(속성)와 행위(메서드)를 정의하고 이를 캡슐화하여 객체를 생성하고 다룰 수 있게 합니다.
- 클래스는 상속을 통해 기존 클래스를 확장하고 다형성을 지원하여 유연한 코드 구조를 구현할 수 있습니다.
- 클래스는 여러 객체를 생성하고 관리함으로써 코드의 구조를 향상시키고 재사용성을 높입니다.
- 왜 클래스를 사용해야 하는가?
- 코드의 구조화: 클래스를 사용하면 관련 있는 데이터와 동작을 묶어서 구조화할 수 있습니다. 이는 코드의 가독성을 높이고 유지보수를 용이하게 합니다.
- 재사용성: 클래스는 객체 지향 프로그래밍의 핵심이며, 이를 통해 코드를 재사용할 수 있습니다. 클래스를 사용하면 비슷한 동작을 하는 여러 객체를 생성할 수 있습니다.
- 상속과 다형성: 클래스는 상속을 통해 기존 클래스를 확장하고 다형성을 지원하여 유연하고 확장 가능한 코드를 작성할 수 있습니다.
- 캡슐화: 클래스는 데이터와 해당 데이터를 처리하는 코드를 함께 묶어 캡슐화합니다. 이는 데이터의 무결성을 보장하고 외부로부터의 접근을 제어할 수 있게 합니다.
- 객체 지향 설계: 객체 지향 프로그래밍은 현실 세계의 개념을 모델링하여 프로그래밍하는 방법입니다. 클래스를 사용하면 현실 세계의 개념을 코드로 옮겨 쉽게 이해하고 관리할 수 있습니다.
- 따라서 데이터 분석과 같이 복잡한 작업을 수행하는 경우 클래스를 사용하여 코드를 구조화하고 객체 지향적으로 설계하는 것이 좋습니다.
- 클래스를 사용하면 유연하고 확장 가능한 코드를 작성할 수 있으며, 이는 데이터 분석 작업의 효율성과 유지보수성을 향상시킵니다.
- 3) 클래스의 속성과 메서드
- 클래스(Class)는 객체(Object)를 생성하기 위한 템플릿이며, 메서드(Method)와 속성(Attribute)을 가질 수 있습니다.
- 메서드와 속성은 클래스의 행동과 상태를 정의하는 데 사용됩니다. 여기서 메서드와 속성의 차이를 설명하겠습니다.
- 메서드(Method)
- 클래스 내부에 정의된 함수를 말합니다.
- 메서드는 클래스에 속한 함수이며, 특정 작업을 수행하거나 클래스의 상태를 변경하는 역할을 합니다.
- 메서드는 일반적으로 클래스의 인스턴스(instance)에서 호출되며, 해당 인스턴스의 상태에 따라 동작합니다.
- 일반적으로 self 매개변수를 첫 번째 매개변수로 사용하여 메서드가 속한 인스턴스를 참조합니다.
class Car:
def __init__(self, brand):
self.brand = brand
def start_engine(self):
print(f"{self.brand}의 엔진을 가동합니다.")
# Car 클래스의 인스턴스 생성
my_car = Car("Toyota")
# start_engine() 메서드 호출
my_car.start_engine() # 출력: Toyota의 엔진을 가동합니다.
- 속성(Attribute)
- 클래스나 클래스의 인스턴스에 속한 변수를 말합니다.
- 속성은 클래스나 인스턴스의 상태를 나타냅니다. 즉, 객체의 데이터를 저장합니다.
- 각 인스턴스마다 고유한 값이 가질 수 있는 인스턴스 속성과 클래스에 속한 공유 속성(static attribute)이 있습니다.
class Dog:
def __init__(self, name):
self.name = name # 인스턴스 속성
# Dog 클래스의 인스턴스 생성
my_dog = Dog("Buddy")
print(my_dog.name) # 출력: Buddy
- 4) 클래스가 데이터 분석에서 사용되는 예시
- 클래스는 데이터 분석에서 다양한 용도로 사용될 수 있습니다.
- 주로 데이터의 구조화, 모델링, 분석 작업의 모듈화, 코드의 재사용성 등을 위해 클래스를 활용합니다.
- 데이터 구조화
- 클래스를 사용하여 데이터를 구조화하고 데이터 타입을 정의할 수 있습니다.
- 예를 들어, 주식 데이터를 다룰 때 각 주식을 객체로 표현하고 해당 주식의 종목명, 가격, 거래량 등을 속성으로 정의할 수 있습니다.
class Stock:
def __init__(self, symbol, price, volume):
self.symbol = symbol
self.price = price
self.volume = volume
# 객체 생성
stock1 = Stock("AAPL", 150.25, 100000)
stock2 = Stock("GOOG", 2800.75, 50000)
- 데이터 전처리 모듈화
- 데이터 분석에서 데이터 전처리는 중요한 과정입니다.
- 클래스를 사용하여 데이터 전처리 단계를 모듈화하고 재사용 가능한 코드로 만들 수 있습니다.
- 예를 들어, 데이터 정규화, 결측치 처리, 이상치 제거 등의 작업을 클래스의 메서드로 구현하여 쉽게 사용할 수 있습니다.
raw_data = [1,2,4,5,6,87,2,253654]
class DataPreprocessor:
def __init__(self, data):
self.data = data
def normalize_data(self):
# 데이터 정규화 작업 수행
pass
def handle_missing_values(self):
# 결측치 처리 작업 수행
pass
def remove_outliers(self):
# 이상치 제거 작업 수행
pass
# 데이터 전처리 객체 생성
preprocessor = DataPreprocessor(raw_data)
preprocessor.normalize_data()
preprocessor.handle_missing_values()
preprocessor.remove_outliers()
- 모델링과 분석 작업
- 데이터 분석에서 사용되는 모델링 작업도 클래스를 활용하여 구현할 수 있습니다.
- 예를 들어, 선형 회귀 모델, 분류 모델, 군집화 모델 등을 클래스로 정의하여 모델의 학습, 예측, 평가 등을 각각의 메서드로 구현할 수 있습니다.
- 참고!) 아직까지는 머신러닝에 대한 자세한 개념을 배우지 않았기 때문에 아래와 같이 클래스를 만들어서 머신러닝 모델을 사용할 수 있다는 것만 확인하고 넘어가면 되요! 🙂
class LinearRegressionModel:
def __init__(self, data):
self.data = data
def train(self):
# 선형 회귀 모델 학습
pass
def predict(self, new_data):
# 새로운 데이터에 대한 예측 수행
pass
def evaluate(self):
# 모델 평가 수행
pass
# 선형 회귀 모델 객체 생성
lr_model = LinearRegressionModel(training_data)
lr_model.train()
predictions = lr_model.predict(new_data)
evaluation_result = lr_model.evaluate()
- 이러한 예시들을 통해 클래스가 데이터 분석에서 어떻게 활용되는지에 대한 감을 잡을 수 있습니다.
- 클래스를 사용하여 데이터를 구조화하고 처리하면 코드의 가독성과 유지보수성을 향상시킬 수 있으며, 모델링 작업을 모듈화하여 코드를 재사용할 수 있습니다.
10. 불리언 인덱싱
- 불리언 인덱싱이란?
- 불리언 인덱싱(Boolean indexing)은 조건에 따라 요소를 선택하는 방법 중 하나입니다.
- 이것은 주어진 조건에 따라 배열이나 리스트에서 요소를 선택할 수 있게 해주는 강력한 도구입니다.
- 파이썬에서는 NumPy를 사용하여 불리언 인덱싱을 수행할 수 있고 Pandas에서 데이터를 조건에 맞게 선택할 때 많이 사용합니다. 아래에는 NumPy를 사용한 불리언 인덱싱의 개념과 코드 예시를 제시합니다.
import numpy as np
# 배열 생성
arr = np.array([1, 2, 3, 4, 5])
# 불리언 배열 생성 (조건에 따라 True 또는 False 값을 갖는 배열)
condition = np.array([True, False, True, False, True])
# 불리언 인덱싱을 사용하여 조건에 맞는 요소 선택
result = arr[condition]
# 결과 출력
print("Result using boolean indexing:", result) # 출력: [1 3 5]
# 불리언 인덱싱을 사용하여 배열에서 짝수인 요소만 선택
evens = arr[arr % 2 == 0]
# 결과 출력
print("Even numbers using boolean indexing:", evens) # 출력: [2 4]
- 위의 예시에서는 NumPy를 사용하여 불리언 인덱싱을 수행하는 방법을 보여줍니다.
- 먼저, 배열 **arr**과 조건을 담은 불리언 배열 **condition**을 생성합니다.
- 그런 다음 불리언 인덱싱을 사용하여 조건에 따라 요소를 선택합니다. 마지막으로 선택된 요소를 출력합니다.
- 불리언 인덱싱은 데이터 필터링 및 선택에 매우 유용하며, 데이터 분석에서 자주 사용됩니다.
11. 데코레이션 사용하기
- 1) 데코레이션이란? (사용 비중이 제일 낮은 함수)
- 데코레이터(Decorator)는 파이썬에서 함수나 메서드의 기능을 확장하거나 수정하는 강력한 도구입니다.
- 데코레이터는 함수나 메서드를 인자로 받아 해당 함수나 메서드를 변경하거나 래핑하는 함수입니다. 이를 통해 코드를 더 간결하고 재사용 가능하게 만들 수 있습니다.
- 즉, 기존의 함수를 따로 수정하지 않고도 추가 기능을 넣고 싶을 때 사용합니다.
- 데코레이션은 따로 함수 내부의 구조를 바꾸지 않고 함수 외부에 간단한 명령어를 작성하여 작동이 되기 때문입니다.
- 아래에 데코레이터 구조를 보도록 하겠습니다.
def decorator_function(original_function):
def wrapper_function(**kwargs):
# 함수 호출 전에 실행되는 코드
result = original_function(**kwargs)
# 함수 호출 후에 실행되는 코드
return result
return wrapper_function
- 2) 데코레이션을 사용하는 예시
- 기존의 say_hello() 라는 함수에 @my_decorator 라는 데코레이터를 입혔습니다!
- 물론, my_decorator 라는 데코레이터를 미리 만들어 줘야 겠죠! my_decorator 안에 함수를 하나 더 넣어서 거기에 어떤식으로 코드를 실행할지 작성하면 됩니다!
- 이러한 데코레이터를 한번 만들어 두면 어떤 함수든 따로 수정하지 않아도 간단하게 데코레이터만 추가하여 데코레이터에 명시한 작업들을 수행할 수 있습니다!
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
- 또 다른 예시로는 딥러닝 라이브러리로 유명한 텐서플로우(tensorflow)의 @tf.function이라는 데코레이션 기능입니다!
- 이 데코레이션은 딥러닝 연산을 수행하거나 데이터 연산을 수행할 때 텐서플로우 연산을 사용하는 경우 훨씬 빠른 성능을 제공해주게 됩니다!
- 그 이유는 텐서플로우는 독특한 연산 방식(그래프)을 가지고 있기 때문에 특정 상황에서는 데코레이션으로 이 연산을 활용하여 이 연산 방식을 사용할 수 있습니다.
- 이렇게 하면 경우에 따라 훨씬 빠르게 연산이 되기 때문입니다!
- 참고로, 계산량이 적은 작은 연산이 많이 있는 상황에서 유리하지만 계산량이 큰 연산이 있는 경우에는 속도 향상이 크게 차이나지 않습니다.
- 예를들어 우리가 A → B → C 순로 작업하는 일을 3번 해야 한다고 해봅시다. 이런 경우 무작정 이 순서로 일을 하기보다는 순서를 다시 정리하여 A → A → A 한번, B → B → B 한번, C → C → C 한번 이렇게 일을 하는 것이 똑같은 양의 일을 하더라도 훨씬 효율적일 것입니다. 파이썬에서 그래프 연산을 한다는 것은 연산의 순서를 명확하게 정리함으로써 최적화 하는 과정입니다!
- 따라서 계산량이 적은데 많이 해야 한다면 효과적일 수 있겠지만, 계산량 자체가 크다면 그래프를 만드는게 오래 걸려 (일은 안하고 A,B,C 순서 정리하느라 시간 다 보내는 것과 같은…) 순서를 정리하는 것이 그다지 효과적이지 않을 것입니다 🙂
- 참고로, 계산량이 적은 작은 연산이 많이 있는 상황에서 유리하지만 계산량이 큰 연산이 있는 경우에는 속도 향상이 크게 차이나지 않습니다.
import tensorflow as tf
@tf.function # The decorator converts `add` into a `Function`.
def add(a, b):
return a + b
add(tf.ones([2, 2]), tf.ones([2, 2])) # [[2., 2.], [2., 2.]]
import timeit
conv_layer = tf.keras.layers.Conv2D(100, 3)
@tf.function
def conv_fn(image):
return conv_layer(image)
image = tf.zeros([1, 200, 200, 100])
print("Eager conv:", timeit.timeit(lambda: conv_layer(image), number=10))
print("Function conv:", timeit.timeit(lambda: conv_fn(image), number=10))
print("Note how there's not much difference in performance for convolutions")
- 참고) 파이썬의 즉시 실행모드와 그래프 모드
- 즉시 실행 모드 (Eager Execution)
- 즉시 실행 모드는 파이썬 코드를 순차적으로 실행하면서 연산을 즉시 평가하는 방식입니다.
- 각각의 연산은 실행될 때마다 결과가 즉시 반환되어 사용자가 바로 확인할 수 있습니다.
- 파이썬의 일반적인 제어 흐름과 함께 사용되며, 디버깅 및 코드 작성이 용이합니다.
- TensorFlow 2.0부터는 즉시 실행 모드가 기본적으로 활성화되어 있습니다.
- 그래프 모드 (Graph Mode)
- 그래프 모드는 파이썬 코드를 그래프로 변환하고, 이를 최적화한 후에 실행하는 방식입니다.
- 먼저 그래프를 정의하고, 그래프를 실행하기 위해 세션을 통해 입력을 제공해야 합니다.
- 그래프는 연산의 순서와 의존성을 명확하게 표현하므로, 병렬 실행과 하드웨어 가속화에 최적화되어 있습니다.
- TensorFlow 1.x에서는 주로 그래프 모드를 사용했으나, TensorFlow 2.0부터는 즉시 실행 모드가 기본으로 제공되어 그래프 모드를 명시적으로 사용하지 않아도 됩니다.
- 차이점
- 즉시 실행 모드는 파이썬 코드를 사용하여 연산을 즉시 평가하고 결과를 반환합니다. 반면에, 그래프 모드는 그래프를 먼저 정의하고 세션을 통해 실행해야 합니다.
- 즉시 실행 모드는 디버깅과 코드 작성이 용이하지만, 그래프 모드는 병렬 실행과 하드웨어 가속화에 최적화되어 있습니다.
- 즉시 실행 모드는 각각의 연산을 바로 평가하기 때문에 코드를 작성하고 실행하는 데에 편리합니다. 반면에, 그래프 모드는 전체 그래프를 먼저 정의하고 실행해야 하므로 초기 설정이 더 복잡할 수 있습니다.
- 그래프 모드는 동일한 그래프를 여러번 실행할 때 재사용할 수 있어서 효율적인 반복 작업에 유용합니다.
- 즉시 실행 모드 (Eager Execution)
12. 파이썬 에러 대처법
- 1) 파이썬 에러 확인하는 법
- 파이썬 에러의 예시
Traceback (most recent call last):
File "codeit.py", line 12, in <module> # 어떤 파일에서 몇번째 줄에 에러가 떴는지를 알려줌
numbers[right] = temp[left] # 어떤 코드가 잘못 되었는지를 알려줌
TypeError: 'int' object is not subscriptable # 에러의 종류 : 에러에 대한 세부 정보
- 위 코드에서는 **‘TypeError’**라는 에러의 종류를 알려주고 있으며
- 세부 정보로 'int' object is not subscriptable임을 알려주고 있음
- 기본적으로 정수형을 인덱싱 하려고 하면 다음과 같은 에러가 뜹니다.
- 의도치 않게 Squence Type의 데이터가 아닌 정수형의 데이터를 인덱싱 해버리는 코딩 실수를 했음을 추측할 수 있습니다.
- 2) 대표적인 에러들
- 1. SyntaxError (구문 오류):
- 에러 메시지: 코드 문법에 오류가 있음을 나타냅니다.
- 대처법: 코드의 문법을 확인하고 괄호, 따옴표, 콜론 등을 올바르게 사용했는지 확인하세요. 코드 블록의 들여쓰기도 확인해야 합니다.
- 잘못된 코드 예시
- 1. SyntaxError (구문 오류):
print("Hello World'
에러메시지
SyntaxError: EOL while scanning string literal
- 2. IndentationError (들여쓰기 오류):
- 에러 메시지: 코드 블록의 들여쓰기가 잘못되었음을 나타냅니다.
- 대처법: 들여쓰기를 일관되게 맞추세요. 보통 스페이스 4개 또는 탭을 사용합니다.
- 잘못된 코드 예시
def my_function():
print("Hello World!")
에러메시지
IndentationError: expected an indented block
- 3. NameError (이름 오류):
- 에러 메시지: 정의되지 않은 변수나 함수를 사용하려고 할 때 발생합니다.
- 대처법: 사용된 변수나 함수가 정의되었는지 확인하세요. 오탈자나 변수명의 대소문자를 확인하고, 정의되지 않은 변수나 함수를 정의하세요.
- 잘못된 코드 예시
# 위에 my_variable에 대한 변수에 대해 따로 언급한 것이 없는 상황
print(my_variable)
에러메시지
NameError: name 'my_variable' is not defined
- 4. TypeError (타입 오류):
- 에러 메시지: 데이터 타입이 일치하지 않는 연산이나 함수 호출을 시도할 때 발생합니다.
- 대처법: 연산이나 함수 호출에서 사용되는 데이터 타입을 확인하고, 필요한 형 변환을 수행하세요. 예를 들어, 문자열과 숫자를 연산할 때는 문자열을 숫자로 변환해야 합니다.
- 잘못된 코드 예시
result = "10" + 20
에러메시지
TypeError: can only concatenate str (not "int") to str
- 5. IndexError (인덱스 오류):
- 에러 메시지: 리스트나 튜플에서 존재하지 않는 인덱스를 접근하려고 할 때 발생합니다.
- 대처법: 인덱스 범위를 확인하고, 존재하지 않는 인덱스에 접근하는 것을 피하세요. 리스트 슬라이싱을 사용하여 안전하게 데이터에 접근할 수도 있습니다.
- 잘못된 코드 예시
my_list = [1, 2, 3]
print(my_list[3])
에러메시지
IndexError: list index out of range
- 6. KeyError (키 오류):
- 에러 메시지: 딕셔너리에서 존재하지 않는 키를 사용하려고 할 때 발생합니다.
- 대처법: 사용되는 키가 딕셔너리에 존재하는지 확인하세요. 딕셔너리에 존재하지 않는 키를 사용하지 않도록 주의하세요.
- 잘못된 코드 예시
my_dict = {"a": 1, "b": 2}
print(my_dict["c"])
에러메시지
KeyError: 'c'
- 7. FileNotFoundError (파일을 찾을 수 없음 오류):
- 에러 메시지: 파일을 찾을 수 없을 때 발생합니다.
- 대처법: 파일 경로를 올바르게 지정했는지 확인하세요. 파일이 존재하는지, 경로가 정확한지 확인하세요.
- 잘못된 코드 예시
with open("nonexistent_file.txt", "r") as file:
contents = file.read()
에러메시지
FileNotFoundError: [Errno 2] No such file or directory: 'nonexistent_file.txt'
- 3) 위의 예시에도 없는 문제라면?
- 무조건 구글링!
- 특히, 에러에 대한 세부정보만 쳐도 그에 대한 해결책이 아주 많음! (다들 그런식으로 실수를 많이 해봤다는 것..ㅎ)
- 만약 세부정보를 검색했는데 나오지 않았다는 것은 흔한 에러가 아니라는 것…! 혹은 찾았더라도 너무 어려운 내용이거나 이해하기 힘들때도 있음…!
- 이 때는 최대한 에러타입만을 보고 추측해서 찾아야 합니다…ㅜㅜ
- (물론, 여러분들은 튜터님에게 찾아가는 추가 선택지가 있죠 🙂)
- 무조건 구글링!
12. Quiz
✔️ 잘 이해 했는지 간단한 퀴즈와 함께 알아봅시다!
1) 파일 불러오기
1. 파일 불러오기 및 저장하기’**의 **‘3)파일 저장하기’**에서 저장 했던 파일들을 불러오세요!
2) 리스트 캄프리헨션
1. 다음 코드의 출력은 무엇입니까? (코드를 치지 않고 예측해보세요!)
squares = [x**2 for x in range(1, 6)]
print(squares)
a) [1, 4, 9, 16, 25]
- 3) 패키지
- 파이썬에서 패키지의 역할은 무엇입니까?
a) 프로그램의 실행 속도를 향상시키기 위해 사용됩니다.
b) 코드의 재사용성을 높이기 위해 사용됩니다.
c) 데이터베이스 관리를 위해 사용됩니다.
d) 네트워크 통신을 위해 사용됩니다.
- 4) glob
- 다음 중 glob 함수의 사용 예시로 올바른 것은 무엇입니까?
a) 파일 삭제
b) 파일 생성
c) 파일 검색 및 패턴 매칭
d) 파일 압축하기
- 5) 클래스
- 평균 계산기
- 아래의 데이터와 클래스 일부분을 수정하여 평균을 계산하는 클래스를 완성하고 실제로 클래스를 선언하여 계산된 결과 까지도 출력해 보세요!
- 평균 계산기
# 데이터는 이것을 사용하세요
data = [2, 4, 6, 8, 10]
class DataPreprocessor:
def __init__(self, data):
self.data = data
def calculation(self):
data_average = sum(self.data) / len(self.data)
return data_average
답)
preprocessor = DataPreprocessor(data)
average = preprocessor.calculation()
print("평균:", average)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
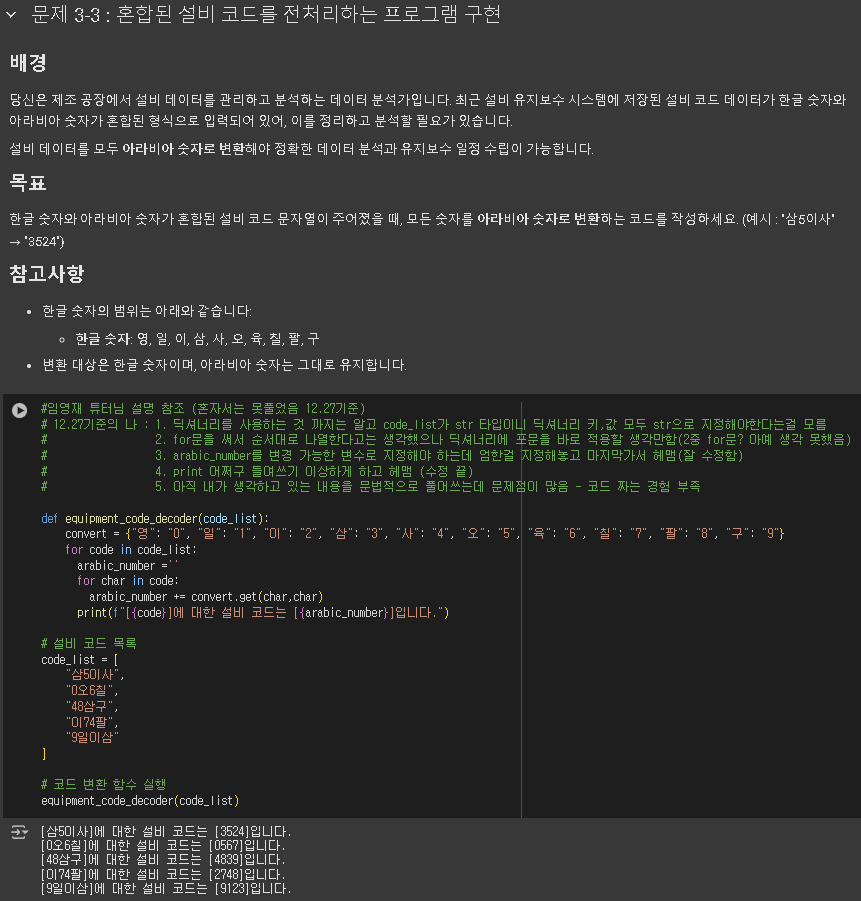
과제 풀기
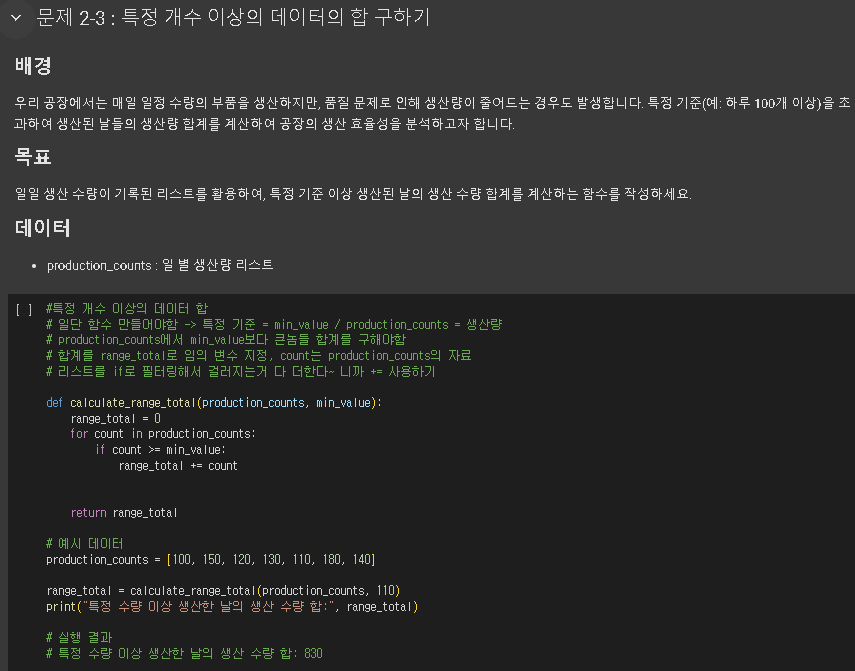
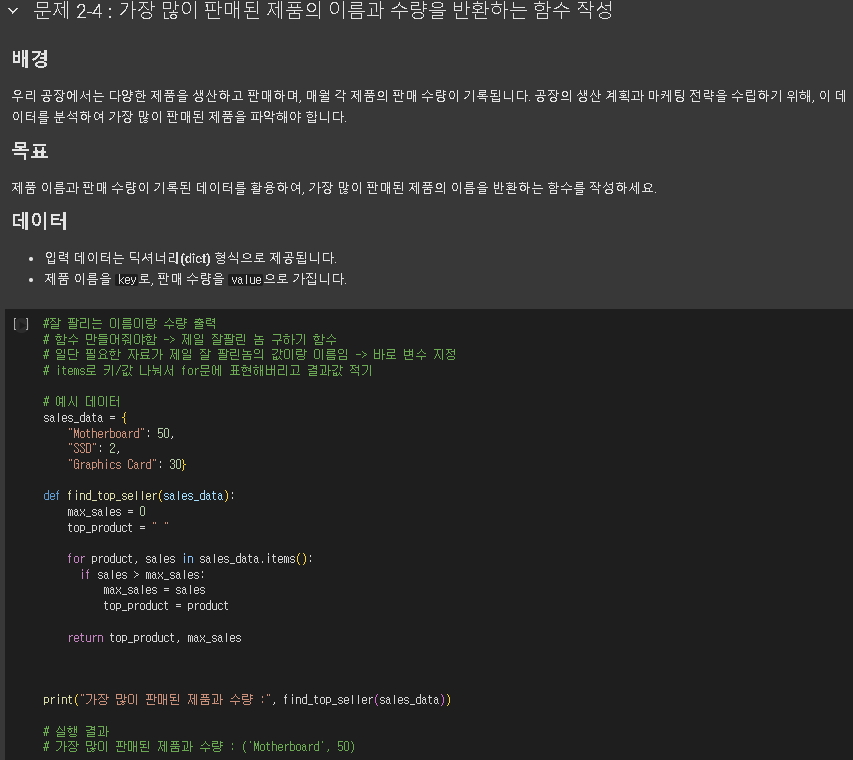
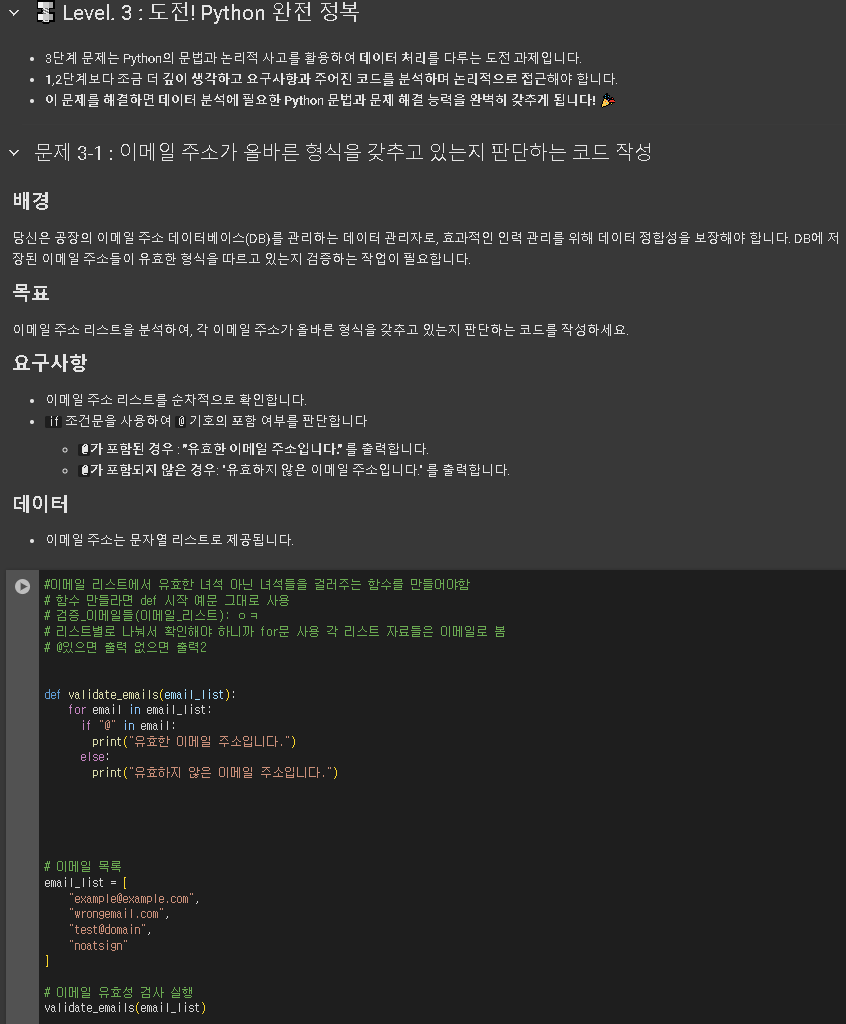
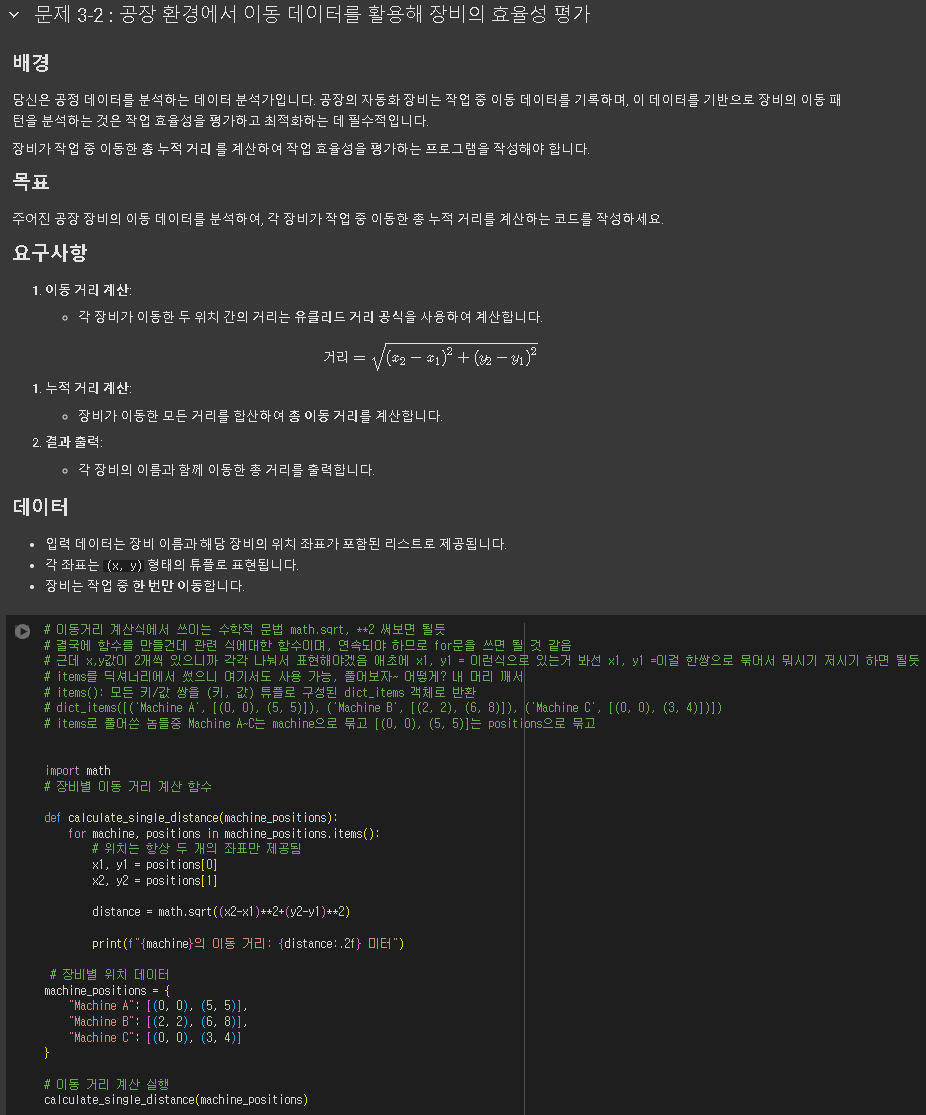
'본 캠프 TIL' 카테고리의 다른 글
| 12월 30일 TIL (6) | 2024.12.30 |
|---|---|
| 데이터 분석 파이썬 종합반 개념정리 1주차~3주차 (0) | 2024.12.27 |
| 12월26일 TIL (2) | 2024.12.26 |
| 12월24일 TIL (1) | 2024.12.24 |
| 12월23일 TIL (4) | 2024.12.23 |