데이터 전처리 및 시각화 과제
* 코랩 사용법
파일을 구글 드라이브에 넣어둬서 동기화를 통해 파일을 가져오면 언제든 편하게 코랩 자료를 쓸 수 있음
답안 , 풀이
문제풀이.ipynb - Colab
https://colab.research.google.com/drive/1HAEDpLoAykk9jxBC642q4yPnoW-On3iC?usp=sharing
데이터 전처리 및 시각화 과제 이유환 - Colab
Level. 1 : 데이터 전처리
공장 데이터(Defects, Temperature 등)를 포함한 CSV 파일을 읽어와, 품질 분석에 앞서 필수적으로 수행해야 하는 전처리 작업을 진행합니다.
결측치 처리 : Defects 열의 이상치로 추정되는 특정 값을 NaN으로 대체하고, Temperature의 결측값은 평균값으로 채웁니다.이상치 식별 : IQR(Interquartile Range) 기법을 이용해 Defects 열에서 이상치를 찾아 얼마나 있는지 확인해봅니다.
데이터 셋 : manufacturing_data_400
요구 사항
CSV 파일 읽기 및 데이터 기본 확인
CSV 파일을 읽어 DataFrame(df) 을 생성합니다.
데이터셋 미리보기 : df의 상위 5개 행을 출력하세요.
데이터 정보 : 컬럼명, 데이터 타입, 결측치 등 기본 정보를 출력하세요.
기술 통계 : 평균, 표준편차, 최소/최대값 등 기술 통계를 출력하세요.
결측값 개수 : 각 열별로 결측값이 몇 개인지 출력하세요.
중복 행이 몇 개인지 출력하세요
import pandas as pd
# 1) CSV 파일을 읽어 DataFrame 생성 (Data는 manu)
manu = pd.read_table ( 'manufacturing_data_400.csv' , sep= ',' )
# 2) df의 상위 5개 행을 확인하고 출력
manu.head ( 5 )
# 3) df의 기본 정보(컬럼명, 데이터 타입, etc.) 출력
manu.info ()
# 4) df의 기술 통계(평균, 표준편차 등) 출력
### manu.groupby('Production').mean() 평균 에러 뜸
### 기술 통계 : 평균, 표준편차, 최소/최대값 등 기술 통계를 출력하세요.
manu.describe ()
# 5) df의 컬럼별 결측값 개수 출력
##isnull 이랑 dropna 예상
manu.isna () . sum ()
# 6) df의 중복 행이 몇 개인지 출력
###duplocated 까먹었음 검색해서 확인
manu.duplicated () . sum ()
결과
+ 다른 풀이법 :
df=pd.read_csv('경로복사')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
df.head()
df.info()
df.describe() : 이상치 9999 발견
df.isna().sum() = df.isnull().sum() : 결측값(null) 총 28개 출력
df.duplicated().sum() : 중복값 총 0개 출력
문제 1-2 : 결측치 처리
요구사항
Defects 열에 이상치로 추정되는 9999 라는 값을 발견했습니다.
Temperature 열에 존재하는 결측치(또는 NaN)을 Temperature 열의 평균값 으로 대체
# 1) Defects 열에서 9999 -> NaN으로 대체
### 기억 안나서 강의자료 확인
### manu[manu['Defects']==9999] = manu[manu['Defects']==''] -> 안됨
### 이게 맞나? 정수 타입에 문자 넣는게? 애초에 NaN 으로 대체면 빈칸으로 만들라는 소리 아닌가..
### 일단 해보고 오류나면 다시 시작하자 manu[manu['Defects']=="NaN"] -> 안됨
### 애초에 Defect 열만 수정되야 하는데 해당 행 전체가 수정됨 왜?
### 일단 위치 지정에 문제가 있는것 같음
### 위키독스 참조 fillna 쓰자 9999는 결측값이 아니라 못씀! 어우!!! 기본이라매요ㅠ
# manu.fillna(value:None,method=None,axis=None,axis={:3},inplace=False,limit=None,downcast=Nome)
# 검색 -> replace 참고
manu = manu.replace ( 9999 , '' )
manu
# 예스! 시간 엄청 부족해요! 여러 데이터 실습해서 익혀야함!
# 2) Temperature 열 결측치를 해당 열의 평균값으로 대체
#mean_tem = manu['Temperature'].mean()
#none_tem = ['Temperature']==''
#manu[manu['Temperature']==''] = manu[manu['Temperature']==mean_tem]
#manu['Temperature'].head(40)
### 왜 NaN가 그대로 나오지? 변경이 안됨 이것도 replace 해보자
## 근데 replace 쓰면 돌아가는 느낌이 있음 처음 1) 문제부터 수정해서 만들고 나중에 NaN 나오도록 또 replace해줘야함
## replace 가 맞나? 더 짧은게 있을텐데? 위키독스 보고 다르게 해보자
#manu.replace(to_replace = manu['Temperature']=='',
# value = manu['Temperature'].mean(),
# inplace = False)
# manu.replace(to_replace={manu['Temperature']=='':manu['Temperature'].mean()}) // manu['Temperature']==''이것들 못씀 인식 안되니까 manu['Temperature']==''도 못쓴듯?
# manu.replace(to_replace={none_tem:mean_tem}) -> 다 안됨
#그냥 열 꺼내서 값 변경해버리자 이런 (열꺼내서 replace 해도 안됨)
#tem = manu['Temperature']
#for i in tem:
# if i == '':
# print(tem.mean())
# else:
# print() -> 안됨
# 재검색 맞다 filllna 쓸 수 있구나 None 값이니까
manu [ 'Temperature' ] =manu [ 'Temperature' ] .fillna ( manu [ 'Temperature' ] .mean ())
manu.head ( 40 )
# 나왔다 ㅠㅠ
결과
오답노트 + 다른 풀이법 :
df['Defects'] = df['Defects'].replace(9999, np.nan)
mean_temp = df [ 'Temperature' ] .mean ()
df [ 'Temperature' ] = df [ 'Temperature' ] .fillna ( mean_temp )
* 합쳐서 만들면 오류날 수 있으니 천천히 나아가자
문제 1-3 : 이상치 식별 (IQR)
요구사항
사분위수 계산
Defects 열의 25% 사분위수(Q1)와 75% 사분위수(Q3)를 구합니다.
IQR(Interquartile Range) = Q3 - Q1 을 계산합니다.Lower Bound = Q1 - (1.5 × IQR), Upper Bound = Q3 + (1.5 × IQR)을 계산합니다.
이상치 데이터 추출
Defects 값이 Lower Bound 미만이거나 Upper Bound 초과인 경우를 이상치로 간주하고, 이상치 데이터 를 추출합니다.
이상치에 해당하는 행이 몇 개인지, 그리고 그 샘플을 출력하세요.
잠깐! IQR이란?
IQR(Interquartile Range)은 데이터의 25% 지점인 Q1과 75% 지점인 Q3의 차이를 의미합니다. 전체 데이터의 중간 50%가 어떻게 분포되어 있는지 파악할 수 있습니다. 이상치(Outlier)를 판단에 주로 활용되는데, 일반적으로 Q1에서 1.5×IQR을 뺀 값보다 작거나, Q3에 1.5×IQR을 더한 값보다 큰 데이터를 이상치로 간주합니다.
import pandas as pd
import numpy as np
# 세션 자료 참고
# 1) 사분위수(Q1, Q3) 계산
#for Defects in manu: -> for 문 쓸까말까 ..
#numeric_Defects = manu.select_dtypes(include=['int64']).columns -> 쓸필요 없나요?
# for Defects in numeric_Defects: -> 강의 자료는 for 문 썼는데 안써도 되려나? 애초에 강의자료에선 여러개의 열을 다같이 묶어서 계산 했으니
manu [ 'Defects' ] = pd.to_numeric ( manu [ 'Defects' ], errors= 'coerce' )
manu_clean = manu [ 'Defects' ] .dropna ()
q1 = manu_clean.quantile ( 0.25 )
q3 = manu_clean.quantile ( 0.75 )
iqr = q3 - q1
lower_bound = q1 - ( 1.5 *iqr )
upper_bound = q3 + ( 1.5 *iqr )
# manu_clean = manu['Defects'].dropna() 이거 안써도 잘만 됐는데 갑자기 오류 나서 뚱뚱하게 수정했어요
# 2) 이상치 데이터 추출
# outliers = if (manu['Defects'] < lower_bound) | (manu['Defects'] > upper_bound):
# if 쓰면 왜 안되는거지? if는 변수 설정할때는 못쓰나?
# 변수 설정(리스트나 딕셔너리 등 생성/수정 할 때 쓰이는 조건문 비스므리 있으니 필요없다)
# if는 결과값만 출력해주니까 변수 설정에 쓰일 수 없다 => 맞나요?
#강의자료 대로 ㄱㄱ
outliers = manu [( manu [ 'Defects' ] < lower_bound ) | ( manu [ 'Defects' ] > upper_bound )]
print ( "Outliers Count:" , len ( outliers ))
print ( "Outlier Samples:\n" , outliers.head ())
오답노트 + 다른 풀이법 :
q1 = df [ 'Defects' ] .quantile ( 0.25 )
q3 = df [ 'Defects' ] .quantile ( 0.75 )
iqr = q3 - q1
lower_bound = q1 - ( 1.5 *iqr )
upper_bound = q3 + ( 1.5 *iqr )
df = df [( df [ 'Defects' ] >= lower_bound ) | ( df [ 'Defects' ] <= upper_bound )]
outliers = df [( df [ 'Defects' ] < lower_bound ) | ( df [ 'Defects' ] > upper_bound )]
print ( "Outliers Count:" , len ( outliers ))
print ( "Outlier Samples:\n" , outliers.head ())
Level. 2 : 데이터 시각화
문제 2-1 : Bar Chart : 라인별 Production & Defects
문제 설명
공장 내에는 A, B, C 등 여러 생산 라인(Line) 이 존재하며, 각 라인마다 하루 생산량(Production) 과 불량(Defects) 데이터가 기록됩니다. 라인별로 이러한 데이터를 그룹화하여 생산량과 불량 수치 를 파악하고, 막대 그래프(Bar Chart) 로 시각화하여 비교하려고 합니다.
요구사항
라인별 그룹화
주어진 데이터에서 라인(Line) 을 기준으로 그룹화하세요.
각 라인별 생산량(Production) 과 불량(Defects) 의 총합(합계)을 구하세요.
Bar Chart 작성
X축에는 라인(Line) 을 표시합니다.
Y축에는 생산량(Production) 과 불량(Defects) 의 합계를 나타냅니다.
각 라인별로 두 가지 막대(Production/Defects)를 나란히 배치하여 시각적인 비교가 가능하도록 합니다.
그래프 꾸미기
그래프의 제목(title) 을 적절히 설정하세요.
X축 라벨(xlabel)과 Y축 라벨(ylabel)을 알맞게 설정합니다.
범례(legend)를 추가하여 Production 와 Defects 를 명확하게 구분하세요.
X축에 라인(A, B, C) 이름이 정확히 표시되도록 하세요 (필요에 따라 plt.xticks 등을 사용)
Y축에 대한 격자(grid)를 추가하여 막대의 높이를 쉽게 확인할 수 있도록 합니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#코드를 작성하세요
manu_gro = manu [[ 'Line' , 'Production' , 'Defects' ]] .groupby ( 'Line' ) . sum () .reset_index ()
manu_gro
#manu_gro = manu.groupby('Line')['Production'].sum() 다른 조원 답변 참조용인데 나랑 결이 다름 근데 더 좋음
#빈칸을 작성하세요
bar_width = 0.35
nrow = manu_gro.shape [ 0 ]
idx = np.arange ( nrow )
plt.figure ( figsize= ( 10 , 6 ))
plt.bar ( idx-bar_width/ 2 , manu_gro [ 'Production' ], width=bar_width )
plt.bar ( idx+bar_width/ 2 , manu_gro [ 'Defects' ], width=bar_width )
plt.title ( 'Total Production and Defects by Line' )
plt.xlabel ( 'Line' )
plt.ylabel ( 'Count' )
plt.xticks ( idx , manu_gro [ 'Line' ], rotation= 0 )
plt.legend ([ 'Production' , 'Defects' ],
loc= 'upper left' ,
bbox_to_anchor= ( 0.83 , 1 ))
plt.grid ( axis= 'y' )
plt.show ()
####뭔가 많이 놓치고 갔어요 이것저것 찾아보면서 바꾸다가 나오는대로 만든건데 아무리 생각해도 이상해요
###예제는 바 그래프가 가운데 정렬되서 이쁘게 보이는데 제껀 범례가 LineC를 덮었네요
### 애초에 plt.xticks(rotation=0) 가 불변인데 왜 이렇게 나온걸까요?
### shape란 함수도 처음봐요
결과 (맘에 안듦)
오답노트 + 다른 풀이법 :
manu_gro = manu [[ 'Line' , 'Production' , 'Defects' ]] .groupby ( 'Line' ) . sum () .reset_index ()
이거 좀 많이 짜침
line_production = df.groupby ( 'Line' ) .agg ({ 'Production' : 'sum' , 'Defects' : 'sum' })
line_production.plot ( kind= 'bar' , figsize= ( 10 , 6 )) #axis, sns, .bar, 등 다채로웠음
plt.title ( 'Total Production and Defects by Line' )
plt.xlabel ( 'Line' )
plt.xticks ( rotation= 0 )
plt.ylabel ( 'Count' )
plt.legend ([ 'Production' , 'Defects' ])
plt.grid ( axis= 'y' )
plt.show ()
!!!agg() 함수 공부하자!!! (아직 안함!ㅋ)
다수(여러개)의 함수 사용을 위한 agg() 메서드-pandas(33)
* legend 굳이 안넣어도 자동으로 들어감
문제 2-2 : Pie Chart: 라인별 Production 비중
문제 설명
공장 내 여러 생산 라인(A, B, C)이 전체 생산량(Production)에서 각각 어느 정도의 비중을 차지하는지 파악하기 위해, 파이 차트(Pie Chart) 를 작성하려고 합니다.
요구사항
Pie Chart 작성
파이 차트 를 사용하여 각 라인의 Production 비중을 시각화하세요.각 파이 조각에 라인 이름 과 퍼센트(%) 를 표시하기 위해 autopct='%1.1f%%' 옵션을 사용하세요.
파이 차트의 색상 을 라인별로 다르게 지정하여 구분이 용이하도록 합니다.
그래프 꾸미기
그래프의 제목(title) 을 적절히 설정하세요 (예: "라인별 Production 비중").
불필요한 축 라벨 (예: 축 눈금)을 제거하여 파이 차트가 깔끔하게 보이도록 합니다.그래프의 색상 을 명확히 구분할 수 있도록 설정하세요.
#코드를 작성하세요
# 파이 차트를 사용하여 각 라인의 Production 비중을 시각화하세요
# 각 파이 조각에 라인 이름과 퍼센트(%) 를 표시하기 위해 autopct='%1.1f%%' 옵션을 사용하세요.
# 파이 차트의 색상을 라인별로 다르게 지정하여 구분이 용이하도록 합니다.
#df.iloc[0] : 인덱스 1 출력
#df.iloc[0:2] : 인덱스 0,1 출력
#df.iloc[0:5:2] : 인덱스 0, 2, 4 행 출력
#df.iloc[0, 0:2] : 인덱스 0행 중에 첫번째, 두번째 열 출력
#df.loc[:,'A'] : 전체 행 중 'A' 열의 값 출력
#df.loc['b':'d', 'A':'B'] : b에서 d까지 행 중 A에서 B까지 열 값 출력
import matplotlib.pyplot as plt
x = [ 15060 , 15416 , 15208 ]
y = [ 'LineA' , 'LineB' , 'LineC' ]
plt.figure ( figsize= ( 8 , 8 )) # 사이즈
plt.pie ( x , labels=y , autopct= '%1.1f%%' )
plt.title ( 'Percentage of Production by Line' )
plt.show ()
# 나 계속 아류야 아류 .. ..
# manu_gro를 바탕으로 pop해서 나온걸 써보려했는데 오류때매 막히고 그 외 loc 써서 열 지정할라 했는데 또 안되서 그냥 쉽게 풀어썼어요
결과
오답노트 + 다른 풀이법 :
일단 x,y 변수를 따로 만든 시점부터 오래쓰긴 글러먹은 자료가 됨
이유: 추후 데이터가 업그레이드 되거나 수정 됐을 시 그에 맞춰 그래프 출력이 바로 안나옴
line_production [ 'Production' ] .plot ( kind= 'pie' , figsize= ( 8 , 8 ),
autopct= '%1.1f%%' ,
startangle = 90 )
plt.title ( 'Percentage of Production by Line' )
plt.ylabel ( '' )
plt.show ()
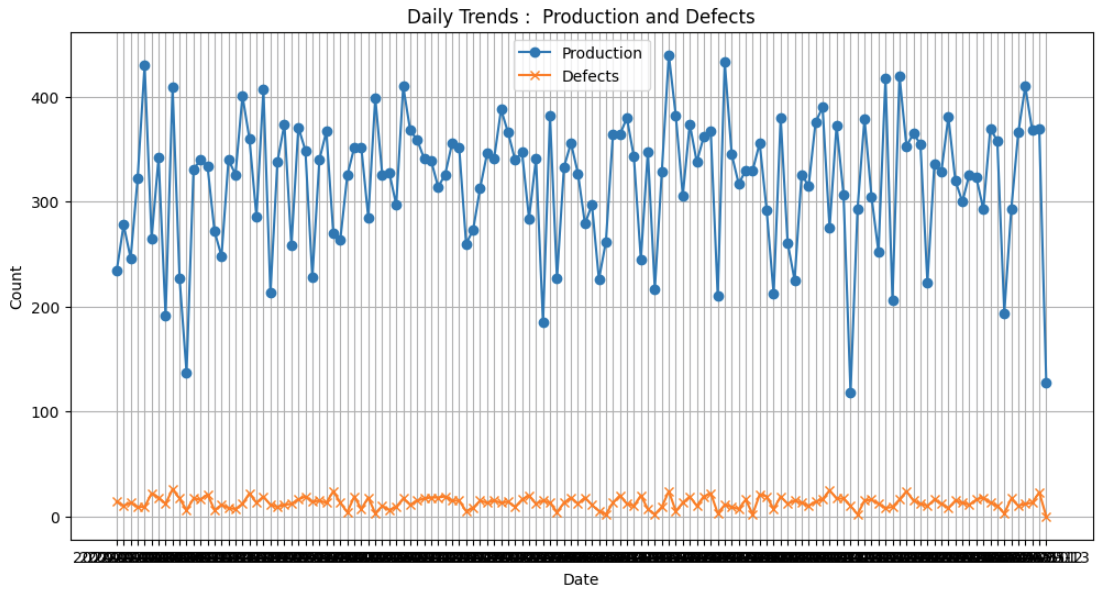
문제 2-3 : 혼합 Line Chart: 일자별 Production & Defects
문제 설명
공장에서는 매일 다양한 제품을 생산하고, 그 과정에서 발생하는 불량 수량 역시 기록합니다. 일자별 생산량(Production)과 불량 수량(Defects) 을 시각적으로 비교하여 불량률 추이와 생산 변동성을 파악하려고 합니다. 이에 따라, 주어진 데이터를 날짜별로 집계하고 선 그래프(Line Chart) 로 나타내는 작업을 수행해야 합니다.
요구사항
날짜별 집계
주어진 데이터에서 “일자(Date)”, “생산량(Production)”, “불량(Defects)”을 날짜별로 그룹화하여 총합(또는 평균)으로 집계하세요.
Line Chart 작성
X축에는 날짜(Date)를, Y축에는 “생산량(Production)”과 “불량(Defects)” 수치를 배치합니다.
날짜별 “Production”을 나타내는 선과 “Defects”를 나타내는 선을 같은 그래프 에 그립니다.
그래프 꾸미기
그래프의 제목(title) 을 적절히 설정하세요.
X축 라벨(xlabel)과 Y축 라벨(ylabel)을 설정합니다.
범례(legend)를 통해 두 선이 어떤 값(Production/Defects)인지 명확히 구분되도록 합니다.
그래프에 격자(grid)를 추가하여 가독성을 높이세요.
복합 그래프 그리는 법?
라인 그래프 작성 코드에 추가하면 됩니다!
# 1) 날짜별 집계
# your code here
x = manu [[ 'Date' , 'Production' , 'Defects' ]] .groupby ( 'Date' ) . sum () .reset_index ()
plt.figure ( figsize= ( 14 , 9 ))
plt.plot ( x [ 'Date' ], x [ 'Production' ], color= 'blue' , linestyle= '-' , marker= 'o' )
plt.plot ( x [ 'Date' ], x [ 'Defects' ], color= 'orange' , linestyle= '-' , marker= 'x' )
plt.title ( 'Daily Trends:Production and Defects' , size= 15 )
plt.xlabel ( 'Date' , size= 13 )
plt.ylabel ( 'Count' , size= 13 )
plt.xticks ( rotation= 0 )
plt.legend ([ 'Total Production' , 'Total Defects' ],
fontsize= 12 ,
loc= 'center left' ,
bbox_to_anchor= ( 0.01 , 0.45 )
)
plt.grid ( axis= 'y' )
plt.grid ( axis= 'x' )
plt.show ()
결과
다른 풀이법 : plt.show()는 코랩에선 내장함수라 안써도됨
daily_production = df.groupby ( 'Date' ) .agg ({ 'Production' : 'sum' , 'Defects' : 'sum' })
plt.figure ( figsize= ( 12 , 6 ))
plt.plot ( daily_production.index , daily_production [ 'Production' ], label= 'Production' , marker= 'o' )
plt.plot ( daily_production.index , daily_production [ 'Defects' ], label= 'Defects' , marker= 'x' )
plt.title ( 'Daily Trends : Production and Defects' )
plt.xlabel ( 'Date' )
plt.ylabel ( 'Count' )
plt.legend ()
plt.grid ( True )
plt.show ()
결과
daily_trend [ 'Production' ] .plot ( kind= 'line' , figsize= ( 14 , 9 ), marker= 'o' )
daily_trend [ 'Defects' ] .plot ( kind= 'line' , figsize= ( 14 , 9 ), marker= 'x' )
plt.title ( 'Daily Trends : Production and Defects' )
plt.grid ( 'x' )
plt.grid ( 'y' )
plt.ylabel ( 'Count' )
plt.legend ()
plt.show ()
결과
daily_trend [ 'Production' ] .plot ( kind= 'line' , figsize= ( 14 , 9 ), marker= 'o' )
daily_trend [ 'Defects' ] .plot ( kind= 'line' , figsize= ( 14 , 9 ), marker= 'x' )
plt.title ( 'Daily Trends : Production and Defects' )
plt.grid ( True , which= 'both' , axis= 'both' , linestyle= '--' , linewidth= 0.5 )
plt.ylabel ( 'Count' )
plt.legend ()
plt.show ()
보조선(grid)가 점선으로 바뀜
질문해야겠다
Q. grid(보조선)가 촘촘하게 나오려면 어떻게 해야하는건지????
A.
Level. 3 : 도전! 한 걸음 더 나아가기
Level. 3 에서 가공한 데이터를 바탕으로 본격적인 시각화를 만들어 봅니다.
Histogram : production 열을 사용하여 Production distribution를 확인합니다.
Pie Chart : 결함률(defect_rate) 데이터를 어느 정도의 비중을 차지하는지 파악하기 위해, 파이 차트(Pie Chart) 를 생성합니다.
한 걸음 더 :전처리와 시각화를 바탕으로 각자의 결론과 인사이트를 자유롭게 적어주세요!각 문제에는 분석가의 해석을 작성하는 공간이 있습니다.
문제 3-1 : Production distribution
요구사항
data_cleaned라는 DataFrame에서 production 열을 사용하여 히스토그램을 작성하세요.
그래프는 2행 3열(subplot(2, 3, 1)) 레이아웃에서 첫 번째 위치에 표시되도록 설정하세요.
막대(bin)의 개수(bins)는 10 으로, 막대 테두리 색(edgecolor)은 'k'(검정색) , 투명도(alpha)는 0.7 로 지정하세요.그래프 제목 (title)은 'Production Distribution' 으로 하고,
x축 라벨: 'Production'
y축 라벨: 'Frequency' 를 각각 설정하세요.
히스토그램이 완성되면, 생산량이 어떤 구간대에 집중되어 있는지 간단히 해석해 보세요. (예: “생산량이 대체로 20~40 구간에 몰려 있다.” 등)
데이터 셋 : data_with_duplicates.csv|
import matplotlib.pyplot as plt
import pandas as pd
# 데이터 로드
data_cleaned = pd.read_table ( '/content/data_with_duplicates.csv' , sep= ',' )
# 결측치 제거
data_cleaned = data_cleaned.dropna ()
# 히스토그램 생성 (확률 밀도로 설정)
plt.figure ( figsize= ( 8 , 6 ))
plt.hist ( data_cleaned [ 'production' ], bins= 10 , edgecolor= 'k' , alpha= 0.7 )
# y축 레이블을 Frequency로 변경
plt.title ( 'Production Distribution' )
plt.xlabel ( 'Production' )
plt.ylabel ( 'Frequency' ) # y축 레이블 설정
# 그래프 표시
plt.show ()
### 뭐가 틀렸길래 Frequency 에 40까지 나오니 ..ㅠㅠ
# 이 에러는 왜 계속 뜰까요 ? 파일 새로 만드니 또 안나와요..
# ---------------------------------------------------------------------------
#TypeError Traceback (most recent call last)
#<ipython-input-103-75ff2c1bca24> in <cell line: 16>()
# 14 plt.figure(figsize=(12,8))
# 15 plt.hist(data_cleaned['production'],bins=10,edgecolor='k',alpha=0.7)
#---> 16 plt.xlabel('Production')
# 17 plt.ylabel('Frequency') # y축 레이블 설정
# 18
#TypeError: 'str' object is not callable
## 생산량은 1000~1025 가장 많고 1225~1250 구간이 1000~1025구간의 30%가량 있다
## 아무리봐도 빈도수가 잘못됐다
결과 틀림
정답
오답노트 + 다른 풀이법 : 전처리 안했음, 왠만해서 한 코드에 다 넣지 말고 코드 나눠서 확인하면서 내려가자, 변수 값은 중복되면 안되니 변수 구분은 필수다
df1 = pd.read_csv ( '/content/data_with_duplicates.csv' )
df1.head ()
df1.info ()
df1.describe () # operation_time_A만 count 60 나오고 나머진 70이니까 결측값 있겠다
df1.isnull () . sum ()
df1.duplicated () . sum ()
df_cleaned = df1.drop_duplicates ()
df_cleaned.duplicated () . sum ()
df_cleaned = df_cleaned.dropna ()
df_cleaned.isnull () . sum ()
df_cleaned.describe ()
plt.hist ( df_cleaned [ 'production' ], bins = 10 , edgecolor = 'k' , alpha= 0.7 )
plt.title ( 'Production Distribution' )
plt.xlabel ( 'Production' )
plt.ylabel ( 'Frequency' )
plt.show ()
문제 3-2 : Defect Rate Category 파이 차트 시각화
요구사항
결함률(defect_rate) 데이터를 구간(binning) 별로 범주화(Category)하십시오.
구간 구분은 [0, 0.015, 0.02, 0.025]로 설정하고, 각 구간에 대한 범주 라벨(labels)은 ['Low (<= 0.015)', 'Medium (0.015-0.02)', 'High (> 0.02)']로 지정하세요.
pandas.cut() 함수를 활용하여, data_cleaned['defect_rate']를 defect_rate_category라는 새로운 컬럼으로 생성하세요.
범주화된 결함률(defect_rate_category)의 각 범주별 빈도수 를 계산하세요. (value_counts() 활용)
파이 차트(Pie Chart)를 그릴 때, 아래 조건을 만족하세요.
차트 크기 : figsize=(8, 6)파이 섹션의 색상 : ['#66b3ff', '#99ff99', '#ffcc99']퍼센트 표시 : autopct='%1.1f%%'시작 각도 : startangle=140차트 제목 : 'Defect Rate Categories'
파이 차트를 통해, 결함률이 어느 구간 에 많이 분포되어 있는지 확인하고, 그에 대한 짧은 해석 을 기술하세요.
예: “대부분의 결함률이 Low (<= 0.015) 구간에 분포한다.”, “약 20%는 High (> 0.02) 범주에 해당한다.” 등
# 라이브러리 불러오기
import matplotlib.pyplot as plt
import pandas as pd
# 구간(binning)과 라벨 설정
defect_rate = data_cleaned [ 'defect_rate' ]
# 결함률 데이터를 범주화하여 새로운 컬럼 생성
#defect_rate['rate1']=pd.cut(defect_rate,bins=[0, 0.015, 0.02, 0.025],
# right=True)
#defect_rate['rate2']=pd.cut(defect_rate,bins=[0, 0.015, 0.02, 0.025],
# right=False)
#defect_rate['rate3'] = pd.cut(defect_rate, bins=[0, 0.015, 0.02, 0.025],
# labels=['Low (<= 0.015)', 'Medium (0.015-0.02)', 'High (> 0.02)'],
# right=False)
bins = [ 0 , 0.015 , 0.02 , 0.025 ]
labels = [ 'Low (<= 0.015)' , 'Medium (0.015-0.02)' , 'High (> 0.02)' ]
defect_rate [ 'defect Group' ] = pd.cut ( data_cleaned [ 'defect_rate' ], bins=bins , labels=labels )
defect_rate [ 'defect Group' ]
ev = pd.concat ([ data_cleaned [ 'defect_rate' ], defect_rate [ 'defect Group' ]], axis= 1 )
ev.columns = [ 'defect_rate' , 'rate' ]
#각 범주별 빈도수 계산
category_count = ev [ 'rate' ] .value_counts ()
# 파이 차트 생성
plt.figure ( figsize= ( 8 , 8 )) # 사이즈
category_count.plot.pie ( autopct= '%1.1f%%' ,
startangle= 90 ,
colors= [ 'lightgreen' , 'orange' , 'lightcoral' ],
wedgeprops= { 'edgecolor' : 'black' })
# 차트 제목 설정
plt.title ( 'Defect Rate Categories' , size= 15 )
plt.ylabel ( '' )
# 차트 표시
plt.show ()
# 분석가의 해석
### 여기에 해석을 입력하세요.
틀림 왜? -> 중복값이 있었는데 전처리 안해서 시~~~!ㅂ
정답
오답노트 :색상 설정 안했고 3-1에서 전처리 안했던것 때문에 결과도 메롱임
plt.figure ( figsize= ( 8 , 6 ))
plt.pie (
defeact_rate_counts ,
labels=defeact_rate_counts.index ,
autopct= '%1.1f%%' ,
colors = [ '#66b3ff' , '#99ff99' , '#ffcc99' ],
startangle = 140
)
plt.title ( 'Defect Rate Categories' )
plt.show ()
느낀점 :
1. 데이터 시각화는 방법이 무궁무진하게 많다
2. 여러 문제를 풀어가며 손에 익숙해져야한다 (하나부터 열까지 아는게 없다)
3. 함수 뭐 쓰면 되겠지 정도론 택도 없다는 생각이 든다
4. 자신감이 떨어졌다 잘해보고 싶었지만 뭐가 부족한거지?
5. 게으름, 세세하게 살피지 않고 넘어간 안일함, 검색 스킬 부족 등
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ,
크로스탭과 피벗테이블 차이
판다스(Pandas)에서 데이터를 재구조화하거나 요약하는 대표적인 방법으로 crosstab과 pivot1. pandas.crosstab
주요 목적 : 범주형 데이터(카테고리) 간의 빈도표 (또는 집계 테이블) 작성함수 형태 : pd.crosstab(index, columns, values=None, aggfunc=None, ...)집계 함수 사용 : aggfunc를 통해 합(sum), 평균(mean), 개수(count) 등 다양한 집계 가능마진(margins) 추가 : margins=True로 전체 합이나 전체 평균 등을 함께 볼 수 있음중복 데이터 : 중복 데이터를 한꺼번에 집계 할 수 있음주로 사용 예시 :
성별, 지역별 판매량 합계
제품 카테고리, 월별 판매 건수 등
간단 예시
import pandas as pd df = pd.DataFrame({
'성별': ['남', '여', '여', '남', '여', '남'],
'도시': ['서울', '부산', '서울', '대구', '부산', '서울'],
'판매량': [100, 150, 200, 130, 170, 160] })
ct = pd.crosstab(
df['성별'], # index
df['도시'], # columns
values=df['판매량'], aggfunc='sum', # 합계를 구함
margins=True # 전체 합 추가 ) print(ct)
2. pandas.pivot
주요 목적 : 데이터를 인덱스와 열 을 기준으로 형상 재구성 (피벗팅)함수 형태 : df.pivot(index=None, columns=None, values=None)집계 기능 없음 : 동일한 인덱스/열 조합에 중복 데이터가 있으면 에러 발생
집계가 필요할 경우 pivot_table 사용
고유 조합(Unique Combination) 필요 : index와 columns가 유일한 조합이어야 함주로 사용 예시 :
시계열 데이터에서 날짜를 인덱스로, 제품명을 열로 하여 판매량을 나열
인덱스와 열을 재배치해서 분석하기 좋게 표 형태 변환
간단 예시
import pandas as pd df = pd.DataFrame({
'날짜': ['2025-01-01', '2025-01-01', '2025-01-02', '2025-01-02'],
'상품': ['A', 'B', 'A', 'B'], '판매량': [100, 150, 200, 130] })
pivot_df = df.pivot(index='날짜', columns='상품', values='판매량') print(pivot_df)
3. 주요 차이점 한눈에 보기특징 crosstab pivot 주 용도 범주형 데이터의 빈도/집계 인덱스와 열을 이용한 데이터 재구조화 함수 형태 pd.crosstab(index, columns, values, aggfunc, ...) df.pivot(index, columns, values) 집계 함수 지원 여부 O, aggfunc 사용 X, 중복 데이터가 있으면 에러 마진(margins) 지원 O, margins=True 옵션 X 인덱스-열 조합 중복 가능 (집계됨) 유일해야 함 (중복 시 에러) 대표적 사용 사례 범주형 변수 간 빈도표, 교차 분석 시계열 또는 특정 기준으로 데이터를 재배열
pivot_table
pivot에서 집계를 하고 싶다면, pivot_table 함수를 사용해야 합니다.
pivot_table은 crosstab처럼 aggfunc를 지정할 수 있으며, 중복 데이터를 집계해줍니다.
pivot_table_df = pd.pivot_table(
df, index='날짜', columns='상품', values='판매량', aggfunc='sum', margins=True )
print(pivot_table_df)
정리
crosstab : 범주형 데이터의 빈도나 합계를 간단히 구할 때 쓰는 교차표 함수로, 중복 데이터를 그룹화해 집계할 수 있음.pivot : 인덱스와 열을 기준으로 데이터를 재배열하기 위한 함수로, 집계 기능이 없음. 중복 데이터가 허용되지 않음.pivot_table : pivot의 확장판으로, 집계가 필요한 경우 사용.
사용하려는 목적이 빈도/집계냐, 단순 재구조화냐에 따라 crosstab과 pivot을 구분해서 쓰고, 집계 기능이 필요하다면 pivot_table을 고려하시면 됩니다.