ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
[챌린지]머신러닝 스킬업 5회차 - 임영재 튜터님
챌린지 5회차
[수업 목표]
- 스마트 팩토리 데이터(삼성 스마트팩토리)를 활용한 데이터 분석
[목차]
- 데이터 불균형 1-1. 개념 1-2. 문제점 1-3. QA / QC관점
- 언더 샘플링과 오버 샘플링의 기법 2-1. 언더 샘플링 2-2. 오버 샘플링
01. 데이터 불균형
1-1. 개념
불균형 데이터란 정상 범주의 관측치 수와 이상 범주의 관측치 수가 현저히 차이나는 데이터를 말합니다.
예를 들면, 센서 데이터에서 결함이 없는 제품(정상) 데이터는 많고, 결함이 있는 제품(불량) 데이터는 매우 적을 때 발생합니다.
1-2. 문제점
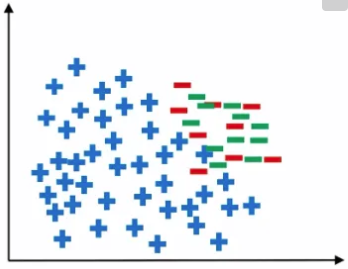
★정상을 정확히 분류하는 것과 이상을 정확히 분류하는 것 중 일반적으로 이상을 정확히 분류하는 것이 더 중요합니다. ★
왜냐하면 보통 이상 데이터가 target값이 되는 경우가 많기 때문입니다.

그림을 봤을 때 파란색은 정상 관측치이고 빨간색은 이상 관측치, 회색은 실제 이상 데이터의 분포를 나타낸 것입니다.
즉, 회색 원은 아직 관측되지 않은 모르는 데이터입니다.
파란색과 빨간색의 데이터만 알고 있는 상태에서 학습을 시킬 경우 분류 경계선은 위의 그림과 같이 그어지게 됩니다.
하지만 경계선 왼쪽의 회색 원들은 실제로는 이상 데이터임에도 정상 데이터로 오분류 됩니다.
경계선은 파란색 원과 회색 원 사이에 그어져야 이상적인 경계선이라 할 수 있습니다.
QA / QC 관점
1. 불균형 데이터의 위험
- 정확도 함정: 불균형 데이터로 학습된 모델은 다수 클래스(정상)에 치우친 예측을 할 가능성이 높습니다.
- 예: 95%가 정상 데이터라면, 모델이 항상 "정상"이라고 예측해도 정확도가 95%가 됩니다.
그러나 불량(5%)은 전혀 감지하지 못합니다.
- 예: 95%가 정상 데이터라면, 모델이 항상 "정상"이라고 예측해도 정확도가 95%가 됩니다.
- 결함 탐지 실패: 소수 클래스(불량)를 충분히 학습하지 못하면 결함 제품을 놓칠 위험이 있습니다. 이는 품질 문제로 이어질 수 있습니다.
2. QA/ QC에서의 목표
- 데이터 균형 유지: 데이터셋을 구축할 때 클래스 균형을 최대한 맞추는 것이 중요합니다.
-> 데이터 증강 기법이나 샘플링 기법을 활용하거나, 생산 환경에서 결함 데이터를 의도적으로 추가 수집합니다. - 평가 지표 개선: 정확도(Accuracy)만으로 모델을 평가하지 않고, 정밀도(Precision), 재현율(Recall), F1-Score 등 불균형 데이터에 적합한 평가 지표를 사용합니다.
- 정밀도(Precision): 예측이 "불량"일 때 실제 불량인 비율.
- 재현율(Recall): 실제 불량 데이터 중에서 모델이 탐지한 비율.
- F1-Score: 정밀도와 재현율의 조화 평균.
ex1) 0과 1에 대한 칼럼이 있을 때 하기 결과는 정확하게 예측한 모델이 아님을 뜻함
accuracy precision recall f1-score
0 0.98 0.98 0.98 0.98
1 0.87 0.01 0.04 0.07
ex2) 결과는 좋으나 실제로 교차검증을 통해 확인을 해야함 (과적합일 확률 매우 높음)
accuracy precision recall f1-score
0 1.0 1.0 1.0 1.0
1 0.98 0.98 0.98 0.98
*** Q. 제품이 이미 만들어지고 불량인지 정상인지 분류하는게 의미가 있나요?
불량인 데이터셋에 대해서 정상과 비교했을 때
1) 어떤 센서값이 문제가 있을 때 불량인지
2) 특정 이상치가 생겼을 때 불량인지 => 이상치 감지 예측모델을 만들어야함
어떤 조건일 때 특정 이상치가 발생하는데 이때 불량이더라
=> 이상치를 조기 발견을 해야겠죠? => 불량 수치를 예방할 수 있는 프로그램
3. QA에서의 해결 방안
- 데이터 수집 전략 강화:
- 소수 클래스(불량) 데이터를 더 많이 수집하는 방안을 마련or 샘플링 기법. -> 데이터 증강, 샘플링 기법 활용
- 생산 환경에서 다양한 불량 케이스를 시뮬레이션하거나 의도적으로 생성.
- 모델 검증 강화:
- 불균형 데이터 상황에서 과소 적합(underfitting)이나 과적합(overfitting)을 방지하기 위한 교차 검증 및 다양한 시나리오 기반 테스트 수행.
02. 언더 샘플링과 오버 샘플링의 기법
데이터가 불균형한 분포를 가지는 경우, 모델의 학습이 제대로 이루어지지 않을 확률이 높음.
이 문제를 해결하기 위해 나온 개념이 언더 샘플링과 오버 샘플링이 있음(과적합 주의, 교차검증 필수)
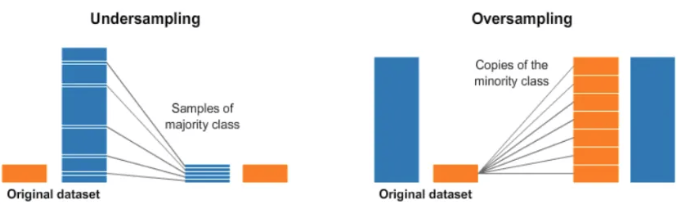
언더 샘플링은 불균형한 데이터 셋에서 높은 비율을 차지하던 클래스의 데이터 수를 줄임으로써 데이터 불균형을 해소하는 아이디어
하지만 이 방법은 학습에 사용되는 전체 데이터 수를 급격하게 감소시켜 오히려 성능이 떨어질 수 있음
오버 샘플링은 낮은 비율 클래스의 데이터 수를 늘림으로써 데이터 불균형을 해소하는 방법.
2-1. 언더 샘플링
언더 샘플링이란 다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 줄이는 샘플링 방식을 말함.
2-1-1. Random Sampling
Random Sampling이란 말 그대로 다수 범주에서 무작위로 샘플링을 하는 것(분류 경계선이 무작위임)

import numpy as np
import pandas as pd
from sklearn.utils import resample
# 예제 데이터셋 생성
data = {'feature1': np.random.randn(1000), # 랜덤 피처 데이터
'feature2': np.random.randn(1000),
'class': [0] * 900 + [1] * 100} # 클래스 불균형 (0: 900개, 1: 100개)
df = pd.DataFrame(data)
# 클래스 분리
df_majority = df[df['class'] == 0] # 다수 클래스 (0)
df_minority = df[df['class'] == 1] # 소수 클래스 (1)
# 랜덤 언더샘플링 (0: 100개, 1:100개 로 줄여서 간다 이중 0:100개 선별의 기준은 랜덤임)
df_majority_downsampled = resample(df_majority,
replace=False, # 복제하지 않음
n_samples=len(df_minority), # 소수 클래스 크기와 동일
random_state=42) # 재현성을 위해
# 언더샘플링 데이터 병합
df_balanced = pd.concat([df_majority_downsampled, df_minority])
print("언더샘플링 전 데이터 분포:")
print(df['class'].value_counts())
print("\n언더샘플링 후 데이터 분포:")
print(df_balanced['class'].value_counts())
2-1-2. Tomek Links
Tomek Links란 두 범주 사이를 탐지하고 정리를 통해 부정확한 분류경계선을 방지하는 방법

다른 클래스의 데이터 두 개를 연결했을 때 주변에 다른 임의의 데이터 Xk가 존재할 때
선택한 두 데이터에서 Xk까지의 거리보다 선택한 두 데이터 사이의 거리가 짧을 때 선택한 두 데이터 간의 링크를 Tomek Link라 부릅니다.

* 어느정도 정상과 이상의 구분이 되어 있어야 가능. 단, 분류 경계선에 겹치는 회색 + 데이터를 이상으로 예측해 안좋음
from imblearn.under_sampling import TomekLinks
import numpy as np
import pandas as pd
# 예제 데이터 생성
np.random.seed(42)
X = np.vstack((np.random.normal(0, 1, (100, 2)), np.random.normal(3, 1, (10, 2)))) # 피처 데이터
y = np.array([0] * 100 + [1] * 10) # 클래스 라벨 (불균형)
# -> 100:10 에서 90:10이 되거나 80:10 이 될수도 있음 아직도 데이터 불균형임
# Tomek Link 적용
tomek = TomekLinks(sampling_strategy='auto') # 다수 클래스 데이터만 제거
X_resampled, y_resampled = tomek.fit_resample(X, y)
# 결과 출력
print("Tomek Link 적용 전 데이터 크기:", X.shape)
print("Tomek Link 적용 후 데이터 크기:", X_resampled.shape)
print("원래 클래스 분포:", pd.Series(y).value_counts())
print("Tomek Link 적용 후 클래스 분포:", pd.Series(y_resampled).value_counts())
2-2. 오버 샘플링
오버 샘플링이란 소수 범주의 데이터를 다수 범주의 데이터 수에 맞게 늘리는 샘플링 방식
2-2-1. Resampling

소수 클래스 데이터를 단순 복제하여 데이터 양을 증가
이 방법은 소수 범주에 과적합이 발생할 수 있다는 단점(복제된 데이터가 기존 데이터와 동일하므로, 데이터 다양성이 낮음)
from sklearn.utils import resample
import pandas as pd
# 데이터 생성
data = {'feature': [1, 2, 3, 4, 5, 6], 'class': [0, 0, 0, 1, 1, 1]} # 클래스 0이 다수
df = pd.DataFrame(data)
# 소수 클래스 분리
df_majority = df[df['class'] == 0]
df_minority = df[df['class'] == 1]
# 랜덤 오버샘플링
df_minority_oversampled = resample(df_minority,
replace=True, # 복제 허용
n_samples=len(df_majority), # 다수 클래스와 동일한 크기로
random_state=42) # 재현성
# 오버샘플링 데이터 병합
df_oversampled = pd.concat([df_majority, df_minority_oversampled])
print("오버샘플링 전 데이터 분포:")
print(df['class'].value_counts())
print("\n오버샘플링 후 데이터 분포:")
print(df_oversampled['class'].value_counts())
2-2-2. SMOTE
SMOTE 방법은 소수 범주에서 가상의 데이터를 생성하는 방법
기존 소수 클래스 데이터를 기반으로, 새로운 데이터를 선형 보간(interpolation)하여 생성.
K값을 정한 후 소수 범주에서 임의의 데이터를 선택한 후
선택한 데이터와 가장 가까운 K개의 데이터 중 하나를 무작위로 선정해 Synthetic 공식을 통해 가상의 데이터를 생성하는 방법 -> 그렇다고 과적합에 자유로운건 아니다
from imblearn.over_sampling import SMOTE
import numpy as np
import pandas as pd
# 데이터 생성 (불균형 데이터셋)
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [10, 10], [20, 20]]) # 특징 데이터
y = np.array([0, 0, 0, 1, 1, 1]) # 클래스 (불균형 데이터)
print("SMOTE 적용 전 클래스 분포:")
print(pd.Series(y).value_counts())
# SMOTE 초기화 (k_neighbors=2)
smote = SMOTE(k_neighbors=2, random_state=42)
# 데이터 오버샘플링
X_resampled, y_resampled = smote.fit_resample(X, y)
print("\nSMOTE 적용 후 클래스 분포:")
print(pd.Series(y_resampled).value_counts())
print("\nSMOTE로 생성된 데이터:")
print(X_resampled)
2-2-3. Borderline SMOTE (SMOTE 업그레이드 vers)
Borderline SMOTE 방법은 Borderline 부분에 대해서만 SMOTE 방식을 사용하는 것
- 소수 클래스 데이터를 Safe, Danger, Noise로 분류
- Safe 관측치:대부분의 이웃이 소수 클래스 → 학습에 문제가 없는 안전한 데이터.
- Danger 관측치:다수 클래스 데이터와 섞여 있어 경계에 위치한 위험한 데이터. (검정색 - )
- Noise 관측치:거의 모든 이웃이 다수 클래스 → 소음 데이터로 간주.

쉽게 말하면, 소수 클래스 데이터 중 경계 근처에 위험한 데이터"만 집중적으로 새로운 데이터를 추가하는 방식
이 외에도.. ADASYN 오버샘플링 기법이있음.(보더라인과 비슷함)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
[베이직] 파이썬 핵심 쏙쏙 - 손보미 튜터님 5회차
베이직 5회차
[수업 목표]
- 데이터분석에서 사용하는 기초 통계 개념을 숙지합니다.
- 다양한 예제 실습을 통해서 통계 코드를 실습합니다.
[목차]
- 베이직 - 파이썬 핵심 쏙쏙 수업 일정
- ADsP 기출문제 풀이
- ADsP 기출문제 총정리
- 정규성
* ADsP 예제 문제
데이터분석 준전문가 기출문제 문제은행 - 뉴비티::새로운 CBT 문제풀이 시스템
1. 데이터 이해
✅ 데이터의 정의와 유형
- 정형 데이터: 표 형태(엑셀, DB)로 저장, 메타 데이터 포함
- 반정형 데이터: JSON, XML, 로그 데이터 등
- 비정형 데이터: 이미지, 영상, 텍스트 등
✅ 데이터 가치와 활용
- 암묵지 & 형식지:
- 암묵지(Tacit Knowledge): 경험적, 문서화 어려움
- 개인에게 축적된 내면화된 지식 => 조직의 지식으로 공통화
- 형식지(Explicit Knowledge): 문서화 가능, 체계적 관리 가능
- 언어, 숫자, 기호로 표출화된 지식 => 개인의 지식으로 연결화
- 내면화=>표출화=>연결화=>공통화
- 1. 암묵지
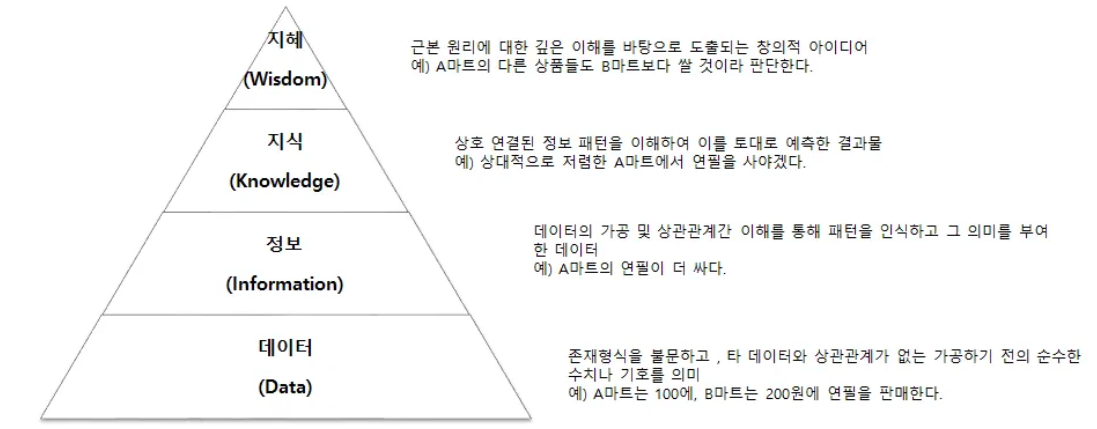
- DKW 피라미드:
- Data → Information → Knowledge → Insight → Wisdom
* 데이터 단위

2. 데이터베이스와 관리
✅ 데이터베이스 개념
- DB와 DBMS로 구성
- DB : 체계적으로 수집. 축적하여 다양한 용도와 방법으로 이용할 수 있게 정리한 정보의 집합체
- (R)DBMS : 이용자가 쉽게 데이터베이스를 구축. 유지할 수 있게하는 관리 소프트웨어
- 데이터베이스의 일반적 특징 / 통합, 저장, 공용, 변화
- 통합된 데이터 : 동일한 내용의 데이터가 중복 x (duplicated 생각)
- 저장된 데이터 : 컴퓨터 매체가 접근할 수 있는 저장 매체에 저장되어 있음.
- 공용 데이터 : 여러 사용자가 공유할 수 있음.
- 변화하는 데이터 : 삽입, 수정, 삭제(CRUD)를 통해 항상 최신의 정확한 데이터를 유지해야 함.
- DBMS 유형:
- 관계형 DBMS (RDBMS): • Oracle(대기업), PostgreSQL(스타트업에서 많이 씀), MySQL(모든기업), Maria DB, SQLite (오픈소스)
- 비관계형 DBMS (NoSQL): • MongoDB(마니씀), Elasticsearch, Redis, Cassandra, HBase, 하둡
✅ 데이터베이스 관리 핵심 개념
- 스키마(Schema): 데이터 구조 및 제약 조건 정의
- 무결성(Integrity): 데이터 정확성 유지 (시험 단골 개념)
- 정규화(Normalization): 데이터 중복 최소화(unique), 효율적 저장
✅ 데이터베이스 설계절차 (개->논->물 순서 외우기)
- 개념적 설계: 개넘적 스키마 생성
- 논리적 설계: ERD 설계
- 물리적 설계: 저장 구조 설계
✅ 데이터 마트 (DM)와 데이터 웨어 하우스 (DW)

- 데이터 웨어하우스
- 분산된 환경에 흩어져 있는 데이터들을 개인이나 조직이 총체적인 관점에서 의사결정을 위해 공통의 형식으로 변환해 관리하는 역할
- 통합, 시계열성, 주제지향적, 비소멸성(비휘발성)
- 데이터 마트 : 데이터 웨어하우스로부터 추출된 작은 데이터베이스, 특정 목표를 달성하는데 필요한 데이터를 제공하는 역할을 함.
✅ 데이터베이스 활용

3. 빅데이터 개요
✅ 빅데이터의 정의와 3V
- 가트너의 3V (시험 단골 개념)
- Volume(규모): 데이터의 크기 (구글 번역 서비스)
- Variety(다양성): 데이터 형태 (정형/비정형)
- Velocity(속도): 실시간 데이터 처리 능력
- 추가 5V: Value(가치), Veracity(신뢰성)
✅ 빅데이터가 만들어낸 변화
- 표본 조사 → 전수조사
- 사전 처리 → 사후 처리
- 질 → 양
- 인과관계 → 상관관계
✅ 데이터 사이언티스트의 필요 역량
- 하드스킬(Hard Skill): 이론적 지식(수학, 통계량, 가설검정 등)
- 소프트 스킬(Soft Skill): 스토리텔링, 리더십, 창의력 등
✅ 빅데이터 가치 패러다임 변화 (순서)
- Digitalization: 아날로그 세상을 디지털화 ( * 참고 관련있는 것 DX : digital transformation )
- Connection: 디지털화 된 정보들의 연결
- Agency: 연결을 효과적으로 관리
2과목
📂 4. 데이터 분석 기획
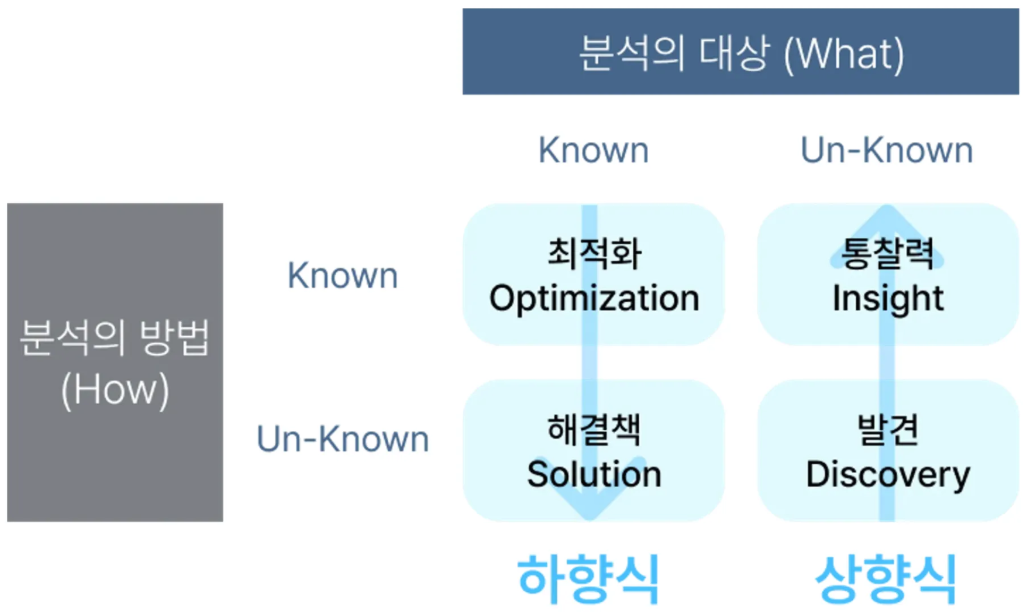
✅ 분석 대상과 방법

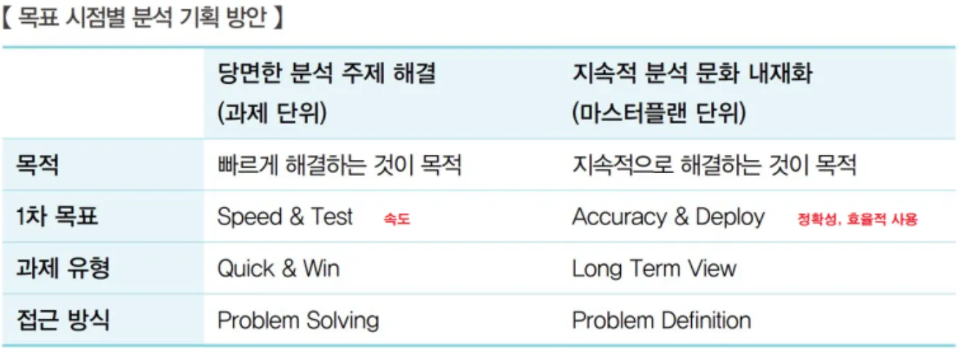
✅ 의사결정을 막는 방해요소3가지
고정관념(Stereotype)
편향된 생각(Bias)
프레이밍 효과(Framing Effect) : 동일 사건이나 상황을 두고 개인 판단이나 선택이 다를 수 있는 현상
✅ 분석방법론 모델
- 폭포수 모델 (Waterfall Model)
- 단계를 거쳐 순차적 진행
- 이전 단계 완료되어야 다음 단계 진행 가능 (하향식 방향)
- 문제, 개선사항 발견될 경우 바로 이전 단계로 돌아가 피드백 수행할 수 있다.
- 프로토타입 모델 (Prototype Model)
- 폭포수 모델의 단점 보완하기 위해 점진적으로 시스템 개발해 나가는 접근 방식
- 고객의 요구 완전히 이해 못하는 경우 프로토타입 모델 적용
- 일부분 먼저 개발해 사용자에게ㅔ 제공, 이후 사용자 요구분석, 정당성 점검, 성능 평가해 개선 작업 시행
- 나선형 모델 (Spiral Model)
- 반복을 통해 점진적 개발
- 프로토타입 모델과 유사하지만 사용자 요구보다 위험요소를 사전제거에 초점.
- 처음 시도하는 프로젝트에는 적용이 용이하지만 관리체계를 효과적으로 갖추지 못하면 복잡도 상승
- 애자일모델 (Agile Model) :
- 끊임없이 시행착오 반복. 고객 반응 민첩 반영. 주기적 프로토타입 관리
✅ KDD 분석 방법론
- KDD(Knowledge Discovery in Database)는 데이터로부터 통계적 패턴이나 지식을 찾기 위해 활용할 수 있도록 체계적으로 정리한 데이터 마이닝 프로세스다.
- 데이터마이닝, 기계학습, 인공지능, 패턴인식, 시각화 등에서 응용 가능한 구조를 가지고 있다.
- KDD 분석 방법론 프로세스데이터셋 선택 > 데이터 전처리 > 데이터 변환 > 데이터 마이닝 > 데이터 마이닝 결과 평가


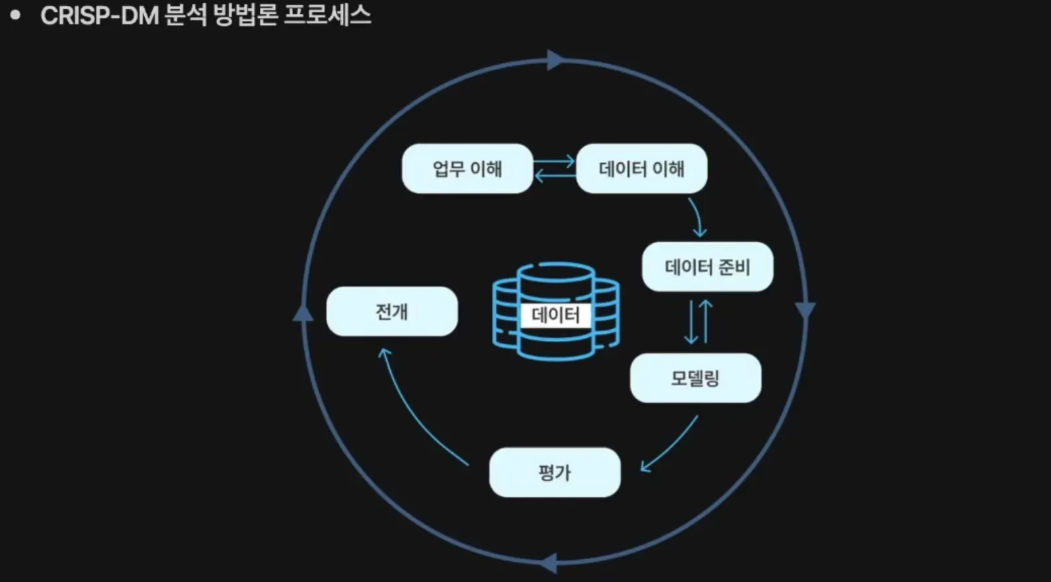
✅ CRISP-DM 분석 방법론
- Cross Industry Standard Process for Data Mining
- KDD와 비슷하나 약간 더 세분화
- 유럽연합에서 1999년에 발표된 계층적 프로세스 모델
- 가장 많이 활용되는 데이터 마이닝 표준 방법론
- 순차적이라기보다, 필요에 따라서 단계 간의 반복 수행을 통해 분석의 품질을 향상시키는 방법론
- 업무 이해 > 데이터 이해 > 데이터 준비> 모델링 > 평가 > 전개
- 모델링: 모델 평가 수행
- 평가 : 모델 적용성 평가 수행



✅ 하향식 접근 방법
- 문제 탐색 > 문제 정의 > 해결 방안> 타당성 검토
✅ 상향식 접근 방법 (잘 모를 때 토의 필요할 때)
- 주로 비지도 학습
- 문제 정의 자체가 어려울 때, 사물을 그대로 인식하는 what 관점
✅ 분석 과제에서 고려해야할 5가지 요소
- 데이터 크기, 속도, 데이터 복잡도, 분석 복잡도, 정밀도/정확도

3. 실습
파이썬 전처리 및 머신러닝(분류) 실습(머신 러닝 관련 코드 참고)
'본 캠프 TIL' 카테고리의 다른 글
| 2월12일 TIL 코드카타 (0) | 2025.02.12 |
|---|---|
| 2월 11일 TIL 프로젝트 완료 (0) | 2025.02.11 |
| 2월 7일 TIL (0) | 2025.02.07 |
| 2월 6일 TIL 코드카타 (0) | 2025.02.06 |
| 2월 5일 TIL 코드카타 (0) | 2025.02.05 |