데이터분석 5주차- 1~7

1. 나이대별 수강률 합 구하기
progress_rate_by_age = sparta_data.groupby('age')['progress_rate'].sum()
progress_rate_by_age
해석 : progress_rate_by_age를 만들 것 이다. sparta_data를 groupby한 것이 필요한데,
('age')별로 ['progress_rate']를 sum()합친것이 필요하다.
그럼 이제 progress_rate_by_age 값 띄워봐
결과.
2. 나이대별 수강생의 인원 구하기
number_people_by_age = sparta_data.groupby('age')['_id'].count()
number_people_by_age
해석 : number_people_by_age를 만들 것 이다. sparta_data를 groupby한 것이 필요한데,
('age')별로 ['_id']들을 count()각각 센 것이 필요하다.
그럼 이제 number_people_by_age 값 띄워봐
결과.
3. 나이대별 수강율 구하기
average = progress_rate_by_age/number_people_by_age
average
해석 : average는 progress_rate_by_age에서 number_people_by_age를 나눈 것 이다.
그럼 이제 average 값 띄워봐
결과.
4. 중복되는 코드가 있으면 원하는 값 도출이 안됨
ex)
#그래프의 x축 눈금 설정
plt.xticks([10,20,30,40,50])
#plt.bar(X축값, Y축값)
plt.bar("x축", "y축")
두 개의 코드가 혼합되어 있으면 그래프 x축을 10,20,30,40,50 으로 기재할지 x축은 "x축" y축은 "y"축으로 기재할지 모름
둘 중 원하는 코드만 남기고 하난 지워야함
x축에 10,20,30,40,50 을 원하므로 plt.bar("x축", "y축")는 삭제해야함
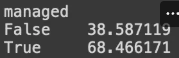
5. 관리 여부에 따라, 수강완료율 평균 구하기
managed_data_avg = sparta_data.groupby('managed')['progress_rate'].sum()/sparta_data.groupby('managed')['_id'].count()
managed_data_avg
해석: managed_data_avg 를 만들 것 이다. sparta_data를 groupby한 것이 필요한데,
('managed')별로 ['progress_rate']를 더한 것에서 ('managed')별로 ['_id']를 각각 더한 것으로 나눌거야.
managed_data_avg 값 띄워봐
결과.
* groupby 함수를 활용하면, 원하는 컬럼을 기준으로 그룹을 묶을 수 있음
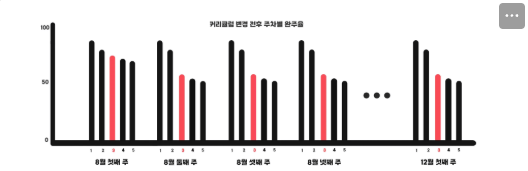
6. 코홀트 cohort 차트 가 왜 필요한가?
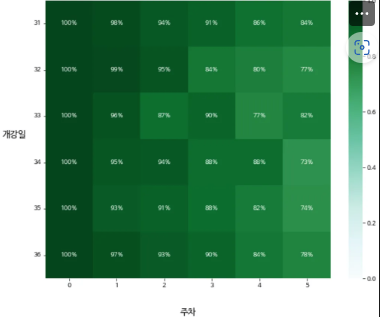
7. 데이터 전처리하기
7-1. created_at 열의 데이터가 시간 형식인지 확인
print(type(sparta_data['created_at][1]))
해석 : print해라 type을 sparta_data에서 created_at열 2번째 데이터의
결과 : <class 'str'>
스트링 즉 문자형식으로 설정되어 있음 시간 형식으로 바꿀 필요성 느낌
해석:
format은 %Y년도. %m월. %d날짜 이다.
sparta_data에 start_time이란 열을 추가할 것인데, 이건 pd. 판다스를 사용한 to_datetime 명령어를 쓸거야 기준은 created_at에 있는 자료가 기준이야, 내가 지정한 format으로 만들건데 infer_datetime_format은 맞아.?(이해 덜됨)
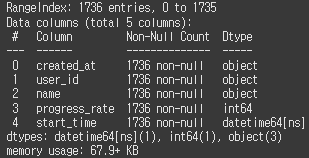
이제 sparta-data.info() 값 띄워봐
결과.
start_time이란 열이 추가됐는데 이 열의 형식은 datetime64 형식이다. 즉 시간&날짜 형식임
* sparta_data.head() 대신 sparta_data.tail()를 기재했을 땐 이렇게 보임
7-2) 수강 시작 주(week)열 추가
sparta_data['start_week']= sparta_data['start_time'].dt.isocalendar().week
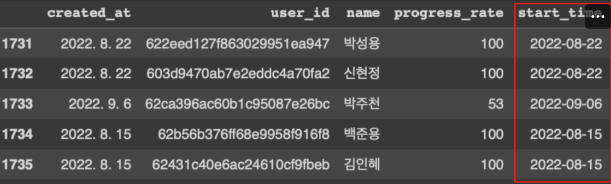
sparta_data.tail()
해석 : sparta_data에 ['start_week'] 열 추가할거야. sparta_data에서 ['start_time']를 기준으로 하는데, dt.isocalendar()의 방식을 쓰고 기재 단위는 week야.
이제 sparta_data의 tail 끝 부분 띄워봐
결과:
(참고 : 8월 22일은 2022년의 34주차가 되는 날)
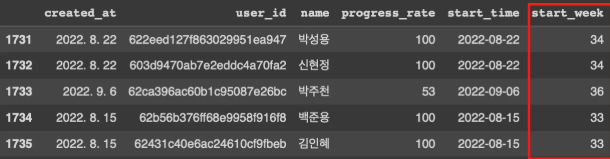
7-2-1) 처음 수강 시작한 주 범위 확인하기
category_range = set(sparta_data['start_week'])
category_range
해석:
category_range를 만들거야. set데이터의 순서가 정해져있지 않고, 중복되지 않은 값이 필요한데 sparta_data의start_week에서 구할거야
category_range값 띄워봐
결과 : {31, 32, 33, 34, 35, 36}
7-1-2) 진도율을 강의 주차로 변경 하기
(1) 진도율 을 강의 주차로 변경
0주차 : 0 ~4 .11% 1주차 : 4.12% ~ 26.03% 2주차 : 26.04% ~ 41.10% 3주차 : 41.11% ~ 61.64% 4주차 : 61.65% ~ 80.82% 5주차 : 80.83% ~ 100%
(2) 범주화 할 데이터 리스트로 만들기
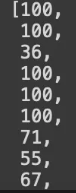
progress_rate = list(sparta_data['progress_rate'])
해석 : 이제 필요없지?
결과 :
.....
(3) 범주를 구분하는 기준 및 라벨(수강 주차) 만들기
#범주를 구분하는 기준 bins 처음(0)과 끝(100) 잊지 말고 기입 해주세요!
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
#구분한 범주의 라벨
labels labes=[0,1,2,3,4,5]
(4) 진도율에 따라 주차별로 변경하기
(4-1) 범주화 하기
#범주화에 사용하는 함수 pd.cut
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labels)
cut
결과:

(4-2) 범주화 결과물을 테이블로 변경하기
#결과물을 테이블로 변경하기
cuts = pd.DataFrame(cuts)
cuts.tail()
(5) 기존 테이블에 현재 수강 주차 테이블 합치기
#concat() 함수를 이용하여, sparta_data 테이블과, cuts 테이블 병합 할수 있습니다 :)
sparta_data = pd.concat([sparta_data,cuts],axis=1, join='inner')
sparta_data.head()
해석: 강의 다시 듣자. axis와 join이 왜 들어가는지 모르겠다.
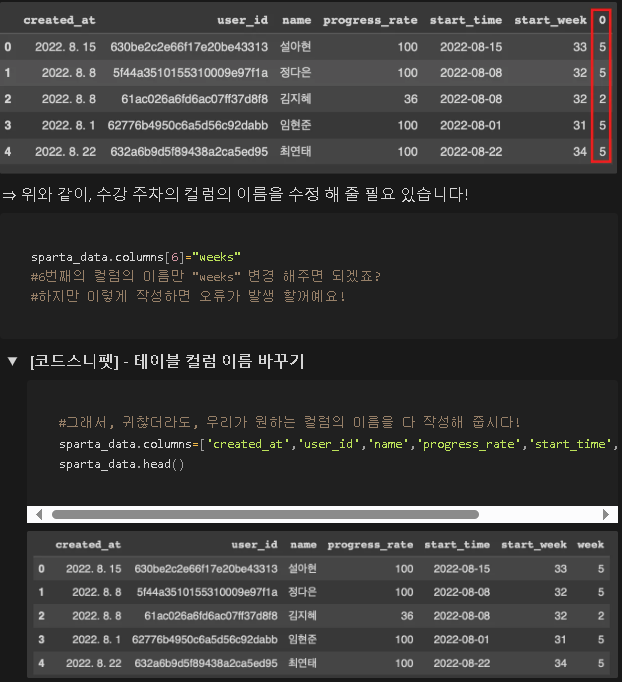
(6) 테이블 컬럼 이름 변경 하기
(시간이 없으니 사진 대체)
*** 잘 기억해두자
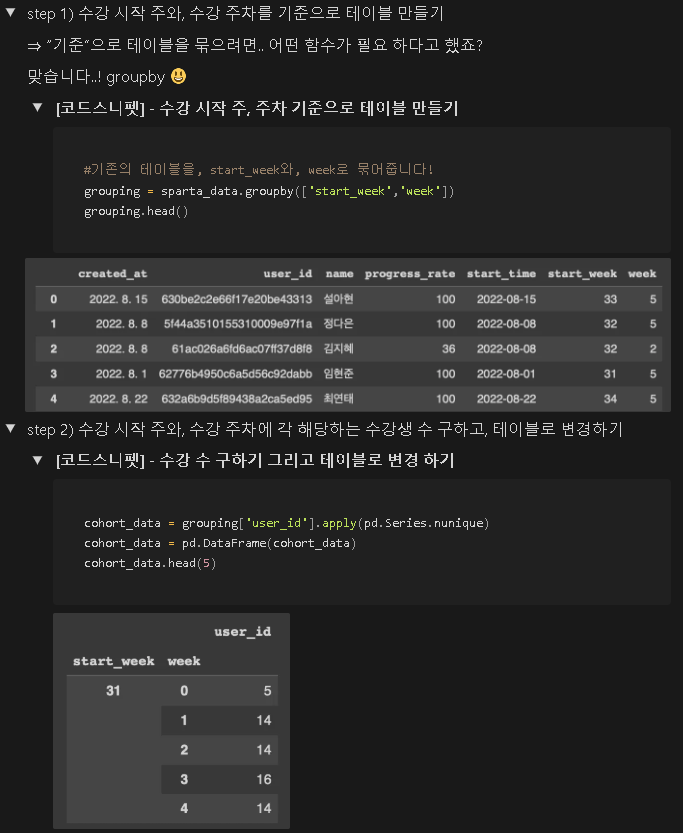
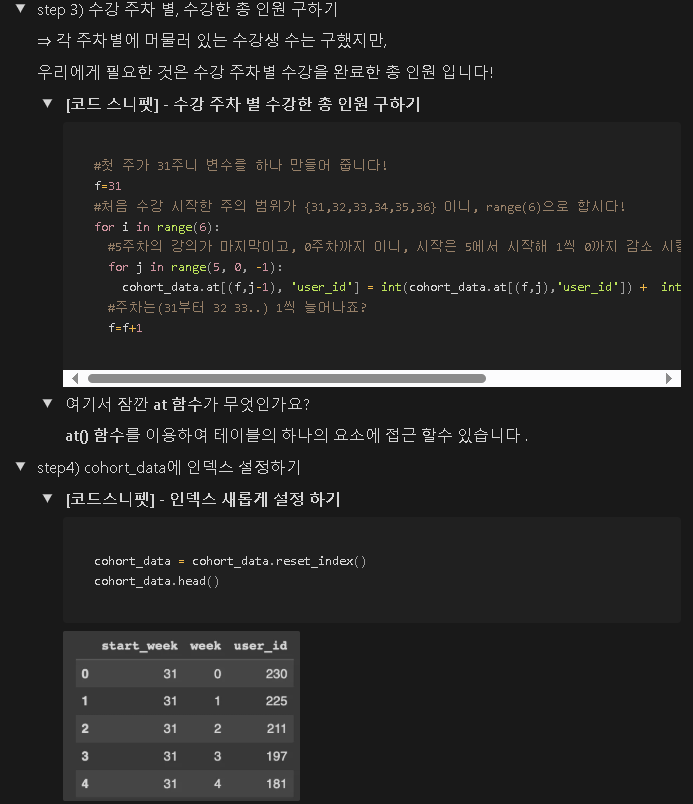
7-4) 데이터 분석
'사전 캠프 TIL' 카테고리의 다른 글
| 12월13일 TIL (사전 캠프 완) (4) | 2024.12.13 |
|---|---|
| 12월12일 TIL (0) | 2024.12.12 |
| 12월9일 TIL (4) | 2024.12.09 |
| 12월6일 TIL (0) | 2024.12.06 |
| 12월 5일 TIL (2) | 2024.12.05 |