데이터 분석 5주차 -7,8 & 숙제
1) 피벗 테이블 만들기
피벗 테이블 :
기존의 데이터를 바탕으로 필드를 재구성해,
데이터 통계를 보다 쉽게 파악 할수 있도록 만든 테이블

cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_counts
해석:
cohort_counts 만들거야.
어떤?
cohort_data에서 pivot피벗 테이블을.
어떻게?
index="start_week", 행은 start_week
columns="week", 열은 week
values="user_id" 내용은 user_id로
만들어진 cohort_counts 보여줘
결과.
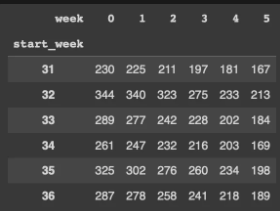
2) 리텐션 테이블 만들기
리텐션 : 고객이 우리 제품이나 서비스를 지속적으로 소비하는 것을 의미
** 피벗 테이블을 리텐션 테이블로 변환 시키는 이유
우리가 고객의 “수”로 고객 수강 이탈을 판단하는건 쉽지 않아요!
그래서, 고객의 행동이 얼만큼 변화가 있는지에 대한 부분을 비율로 나타내면
좀 더 한 눈에 알아 볼수 있는 분석 결과가 됩니다!
2-1) 리텐션 테이블 생성 및 각 데이터에 나눠 줄 수강 시작 주 총 인원 구하기
# 앞서 만든 피벗 테이블을 retention 변수에 저장하기
retention = cohort_counts (리텐션 시작을 알리는 종소리)
#각 주(week) 별 최초 수강생 수만 가져오기 (나눠줄때, 분모가 되는 부분!)
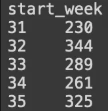
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
해석:
cohort_counts.iloc[:,0]은 cohort_counts에서 iloc위치 지정 좌표는 : 열, 0 첫번째 즉 각 0주차 수강 인원을 뜻함.
결과.
2-2) 각 데이터에 수강 시작 주의 총 인원 나눠주기
각 주당 수강생 수강율 나타내기
# 표의 단일 데이터에 최초 수강생의 수를 나누어, 각 주당 수강생 수강율 나타내기!
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention.head()
해석: cohort_counts를 divide나눌거야. cohort_sizes의 axis=0첫번째 축(열)을 기준으로.
결과.

*** axis 값이 0이 아닌 다른 숫자를 기입 시 오류뜸. cohort_sizes는 첫번째 열 하나만 기재되어 있어서.
그래서 axis 값 0 고정 / 상단 cohort_counts.iloc[:,0]의 값을 cohort_counts.iloc[:,1] 로 변경 시
0주차 나눈 값이 아닌 1주차 기준으로 나눈 값이 테이블로 만들어짐
2-3) 각 데이터 퍼센테이지로 변경하기
#각 수치 퍼센트로 변경하기
#round 함수로 3자리 수에서 반올림 한 후, 100을 곱해 줍니다!
retention.round(3)*100
결과.

3) 코호트 분석 히트맵으로 시각화 하기
목적: 한눈에 알아보려고
연습 :
sns.heatmap(data="필요한 데이터 입력하기",
annot=True, #각 cell의 데이터 표기 유무를 나타냅니다!
fmt='.0%', #values(데이터의 값) 값의 소수점 표기
vmin=0,#최소값 설정
vmax=1,#최댓값 설정
cmap="BuGn" #히트맵의 색을 설정합니다
)
해석 : sns.heatmap만들거야.
필요한 데이터는 retention이고
True를 False로 바꾸면 데이터 표기 안되고 (각 셀마다 색상만 표기됨)
0%를 5%로 변경 시 예를 들어 셀에 표기되는 데이터가 94% 에서 94.3795%로 표기됨
vmin 0은 0%, 0.5는 50% 이다. 테이블의 최솟값은 60.9%가 시작이니까 vmin0 보단 vmin0.5 정도가 눈으로 보기 편함
vmax vmin과 동일
BuGn이 초록색이라는데 난 잘모르겠다 대충 rgb나 뭐시기 색상 쓴다니까 그 종류 중 하나인듯
#테이블 크기 설정 하기
plt.figure(figsize=(10,8))
sns.heatmap(data="필요한 데이터 입력하기",
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
plt.yticks(rotation=360)
plt.show()
결과.

&&&&숙제&&&&&
결론 : 숙제 못함
이유 : 개념 부족, 이해 부족
해결 방안 : 재수강 후 개념, 이해 충전 재숙제 진행
1차 데이터 분석 완강.
수업일 12월3일~12일
2차 데이터 분석 수강 예정일 12~13일
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
2차 데이터 분석 수강
1주차 완강
2-4 판다스 활용한 데이터 분석
상관관계 도표 도출과정
복기한&알게된 것.
1. .isnull().sum() 는 공백란을 합한 값을 구해주는 명령어
2. .dropna() 는 공백란을 없애주는 명령어
3. corr을 correlation의 약자 / :상관관계 pearson은 피얼슨 방법으로 상관관계 구하겠단 소리 (자주쓰임)
4. 생존율 상관관계를 알고 싶은데 생존율&생존율 상관관계는 있어봤자 의미 없으므로 삭제할래
-> corr=corr[corr.Survived!=1] (띄어쓰기 없어도 가능, 느낌표와 1 구분 필요)
2-6 맷플롯리브를 이용한 데이터 분석
(상관관계 도표를 활용한) 그래프 출력 과정
복기한&알게된 것.
1. 그래프 출력 전에는 matplotlib를 실행해두자
2. 단순히 꺾은선 그래프 출력하려면 corr.plot() 정도면 충분
바 그래프 출력하려면 corr.plot.bar() 이면됨
3. 그래프에서 하나의 값에 관한 내용만 알고 싶으면 ex)Survived corr['Survived'].plot()
4. 그래프에서 없애고 싶은 내용 있으면 ex)PassengerId corr=corr.drop['PassengerId'],axis='row')
**** 여기서 axis='rows' 는 PassengerId의 행(의 축)을 없애겠다는 의미
5. 코드가 순서대로 기재되야 얻고 싶은 그래프를 얻을 수 있음
6. plt의 45도 회전시킬 수 있다. 뭘? 그래프 상 x축의 내용을
쓰는 이유? x축 내용이 쓸데없이 너무 길면 글자끼리 겹치니까
2-7 나이대 별로 생존율이 어떻게 다른지 확인하는 방법
복기한&알게된 것.
1. 넘파이는 그냥 기재해둔게 아니라 빠르게 계산 도와주는 라이브러리다 (처리속도 올려준다~)
2. .describe는 도표값의 각 평균/최저/최대/표준편차 등을 나타낼 때 쓰는 명령어다.
3. titanic['Age'].hist(bins=40,figsize=(18,8),grid=True)
이게 뭔가 했는데 타이타닉 나이에 대한 분포도를 나타내주는 그래프 만들 때 쓰이는데 hist는 히스토그램의 약자로
바 그래프는 바 사이의 간격이 있는데 히스토그램은 바 사이의 간격이 없는 그래프다.
bins는 바의 갯수 grid는 기준선 True기재 False삭제 이다.
4. titanic['Age_cat'] = pd.cut(titanic['Age'],bins=[0,3,7,15,30,60,100],include_lowest=True,labels=['baby','children','teenage','young','adult','old'])
(age_cat? 캣은 뭐야 tlba... ) 나이_캣이란 기준 추가할건데, 이건 판다스 이용해서 cut 각각 타이타닉 나이 0,3,7... 기준으로 애,어린이,10대,젊은,청년,늙은 으로 나눌거야 include_lowest=True 최저값은 포함할거야 이 문구 include_lowest=True 는 지금 의미 없어서 삭제해도 상관없어
5. titanic.groupby('Age_cat').mean() 자. 이제 Age_cat 으로 각각 그룹화 한걸 도표 보여줘봐
6. 그래프의 사이즈는 이거야 x축 길이는 14, y축 길이는 5 정도로 만들어
7. 시본 이용한 바플롯 그래프의 x축은 나이_캣으로 y축은 생존한 으로 데이터는 타이타닉에서 가져오는걸로 해
8. 그래프 보여봐
9. plt.figure(figsize=(14,5))
이거 순서 얘가 먼저 들어가야 올바른 그래프 가 만들어짐.
★ ★ ★ ★ ★ ★ ★ ★ ★ ★ 느낌점 ::: ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★
1. 코드를 맛볼순 있는데 왜 이걸 여기서 사용해야만 하는거지? 하는 의문이 해결되지는 않음
-> 짜증남 질문해서 해결될 문제도 아닐 것 같음
=> 예상 질문에 대한 답변 : 코드 처음 설계한 사람 따라 가는거에요~ ti~~~~~~~qk
하단 이부분 순서가 이해 안됨
'사전 캠프 TIL' 카테고리의 다른 글
| 12월13일 TIL (사전 캠프 완) (4) | 2024.12.13 |
|---|---|
| 12월 11일 TIL (0) | 2024.12.11 |
| 12월9일 TIL (4) | 2024.12.09 |
| 12월6일 TIL (0) | 2024.12.06 |
| 12월 5일 TIL (2) | 2024.12.05 |